Mit6.824学习笔记
目录
- 目录
MIT6.824课程
分布系统简述
分布式系统的定义
- 非正式的定义,这里认为多个只能通过网络发送/接收数据包进行交互的系统,(而不是使用多处理核,因为多处理核是可以通过共享内存实现数据的交互的)即构成分布式系统, 它们合作来提供一些服务
为什么使用分布式系统?
- 可以实现数据之间的共享 (sharing)
- 通过并行提高性能(increase capacity though parallelism)(可以将数据分散到多个节点上并行处理。处理海量数据时,传统的单机处理方式无法满足需求,而分布式处理可以将任务划分成小部分,快速处理,从而大大提高性能。)
- 提高服务容错性 (tolerate faults) (本课重点) (一部分服务宕机不会影响到另一个部分服务,具有高可用性)
- 利用物理隔离的手段提高整体服务安全性 (achieve security via isolation)(许多银行会将敏感的客户数据存放在隔离的数据库中,而与外部系统通过API进行通信。通过物理隔离,这些核心数据不暴露在开放的网络上,从而提高系统的安全性,降低数据被攻击或泄露的风险。)
分布式系统的历史
- 局域网分布式系统的服务 (1980s)(类似校园网这种)
- 互联网规模的分布式系统,比如DNS(域名服务系统)、email
- 数据中心 (Data center),伴随大型网站而生 (1990s)
- 常见的有网页搜索(爬虫实现,然后需要建立大量倒排索引)
- 商城购物系统(海量商品、订单、用户信息等数据)
- 云计算 (Cloud computing) (2000s)
- 本地运算/本地运行应用,转移到云服务上运算/运行应用
分布式系统的难点(Chalenges)
网络分区:那么对于一个n个节点组成的网络来说,如果n 个节点可以被分为k个不相交且覆盖的group, 每个group内所有节点全是两两正常连接,而任意两个group之间的任何节点无连接。当k=1 时,网络正常,当k > 1 时,我们称之为network partition。
RabbitMQ集群内两两节点之间会有信息交互,如果某节点出现网络故障或是端口不同,则会使与此节点的交互出现中断,经过超时判定后,会判定网络分区。网络分区的判断与net_ticktime参数息息相关,其默认值为60。集群内部每个节点间会每隔四分之一net_ticktime记一次应答,如果任何数据被写入节点中,则此节点会被认为已经被应答了,如果连续4次没有应答,则会判定此节点已下线,其余节点可以将此节点剥离出当前分区。
对于未配置镜像的集群,网络分区发生之后,队列也会随着宿主节点而分散在各自的分区中。对于消息发送方而言,可以成功发送消息,但是会有路由失败的情况,需要配合mandatory等机制保障消息的可靠性,对于消息消费方而言,可能会出现不可预知的现象,比如已消费消息ack会失效。网络分区发生后,客户端与某分区重新建立通信链路,其分区中如果没有相应的队列进程,则会有异常报出。如果从网络分区中恢复,数据不会丢失,但是客户端会重复消费。
对于已镜像的集群,网络分区的发生会引起消息的丢失,解决办法为消息发送端需要具备Basic.Return的能力,其次在检测到网络分区之后,需要迅速地挂起所有生产者进程,之后连接分区中的每个节点消费分区中所有的队列数据,在消费完之后再处理网络分区,最后从网络分区中恢复之后再恢复生产者进程。整个过程可以最大程度上保证网络分区之后的消息的可靠性。需要注意的是整个过程中会有大量的消息重复,消费客户端需要做好相应的幂等性处理。也可以将所有旧集群资源迁移到新集群来解决这个问题。
-
许多并发场景 (many concurrent part)
-
需要处理故障/宕机问题 (must deal with partial failure)
-
尤其是发生网络分区问题 (network partition)
-
体现性能优势 (realize the performance benefits)
通常任务并非真正所有步骤都并行执行,需要良好的实现才能达到增加机器数就提高吞吐量的效果
课程介绍
实验内容:
-
Lab1:实现mapreduce
-
Lab2:在存在故障和网络分区的情况下,使用raft协议完成复制
-
Lab3:通过实验2,复制一个Key-Value存储的服务
-
Lab4:构造分片(sharded)的key-value存储服务
支持分布式系统的底层基础架构
- 存储:键值服务器,文件系统等
- 计算:分布式计算框架,用来编排或构建分布式应用程序如MapReduce,Spark等
- 通信:分布式通信框架,使用RPC(远程过程调用):RPC的消息传递语义有三个(它们描述了在分布式系统中,消息如何在客户端和服务器之间进行传递,以及对消息传递保障的不同要求)
- utmost once:最多一次,最多一次的发送消息,不管对方是否收到消息都不会重发
- exactly once:确保一次,确保消息只发送一次,不管对方是否收到消息都不会重发
- at least once:至少一次,至少发送一次,不管对方是否收到消息都发送一次
对于分布式系统的底层基础架构,我们通常抽象的目标是做到让使用者觉得和单机操作无异,这是非常难实现的。(也就是隐藏分布式中各类难题的具体实现,对外暴露时争取和普通本地串行函数别无二致。)
分布式系统的特性
尾部延迟是什么?如何避免尾部延迟? | 程序员技术之旅 (zhangbj.com)<= 简述概念和产生原因
概念:有1%的请求耗时高于99%的请求耗时,影响用户体验,甚至拖垮服务。什么是尾部延迟
我们并行调用N个服务,然后等待最慢的一个。应用我们的直觉表明,随着N的增加,我们等待约100ms缓慢呼叫的可能性越来越大。在N = 1的情况下,发生这种情况的时间约为1%。在N = 10的情况下,大约有10%的时间。在这个简单的模型中,这种基本直觉是正确的。然而,在实际中,我们遇到的情况可能比这个更复杂。
-
容错性:系统在部分节点故障时仍然可以正常运行,通常通过复制和容错机制实现。
- 可用性:一般用p999等指标衡量(p999就是指99.9%,即在所有的请求中,99.9%的请求响应时间都在这个值以下。这意味着只有0.1%的请求响应时间会超过这个值。)
- 主要依赖replication复制技术(例如通过将数据和服务复制到多个节点上,确保即使部分节点发生故障,系统依然能够继续运行。)
- 可恢复性:当机器崩溃或故障时,在重启时恢复正常工作状态
- 主要依赖logging or transaction(日志或事务)一类的技术
- durable storage,需要将数据写入持久化的存储器(磁盘),便于后续恢复工作
- 可用性:一般用p999等指标衡量(p999就是指99.9%,即在所有的请求中,99.9%的请求响应时间都在这个值以下。这意味着只有0.1%的请求响应时间会超过这个值。)
-
一致性:多个服务器应该具有相同的状态,提供一致的服务,不能出现客户端用相同操作请求两个服务器却获得了不同结果的情况。一致性根据程度可以分为最终一致性和强一致性。
- 最终一致性:系统保证在一段时间后,所有节点的数据最终都能达到一致。也就是说不保证在任意时刻数据都是一致的
- 强一致性:系统保证任意时刻,所有节点的数据都是一致的。具体来说,任何一次读操作都能读到某个数据的最近一次写操作的结果。这意味着系统中的所有进程看到的操作顺序都与全局时钟下的顺序一致。例如,在关系型数据库中,更新后的数据必须能被后续的访问立即看到,这就是强一致性
-
性能:分布式系统往往希望能比单机系统要具备更高的性能,但是提高性能本身和提供容错性、一致性是冲突的。
性能指标一般涉及两个方面:吞吐量和延迟。- 吞吐量:系统处理请求的能力,通常用每秒处理请求数(TPS)来衡量。
- 延迟:系统响应请求的时间,通常用平均响应时间(RTT)来衡量。(尾部延迟(上述引文有讲)在分布式系统中尤为重要,因为它会严重影响系统的整体性能。)
为了达到强一致性,需要不同机器之间的通信,这可能降低性能
为了实现容错,需要从不同机器上复制数据,还需要将数据写入持久化存储器这一昂贵操作
通常要兼顾以上3个特性很难做到,常见的实现要么牺牲一点一致性换取更高的性能;要么牺牲一点容错性换取更好的性能,不同的实现方式有不同的权衡。
mapreduce概述
- 论文的背景是google的两位数据工程师需要处理爬虫数据,建立倒排索引,用于网页搜索。需要几个小时处理TB级别的数据。传统的代码实现,并发执行任务,如果中间一个线程出错,可能整个任务都需要重新执行,所以还需要考虑容错性设计。
- 程序员通过编写函数式或无状态的map函数和reduce函数的实现,实现分布式数据的处理。mapreduce内部通过其他机制保证执行过程的容错性、分布式通信等问题,对程序员隐藏这些细节。
- map-reduce经典举例即统计字母出现的次数,多个进程各自通过map函数统计获取到的数据片段的字母的出现次数;后续再通过reduce函数,汇总聚合map阶段下每个进程对各自负责的数据片段统计的字母出现次数。一旦执行了shuffle,多个reduce函数可以各自只聚合一种字母的出现总次数,彼此之间不干扰。
- 开销昂贵的部分即shuffle,map的结果经过shuffle按照一定的顺序整理/排序,然后才分发给不同的reduce处理。这里shuffle的操作理论比map、reduce昂贵。
提问:排序操作是否可以通过map-reduce完成
回答:可以,排序在mapreduce中是讨论最多的应用之一,可以通过mapreduce实现。你可以将输入拆分成不同部分,mapper对这些部分进行排序,输出拆分成r个桶,每个reduce对这r个桶进行排序,最后输出完整的文件。
mapreduce的执行流程
MIT6.824学习笔记<<== 一位大佬对mapreduce的详细介绍
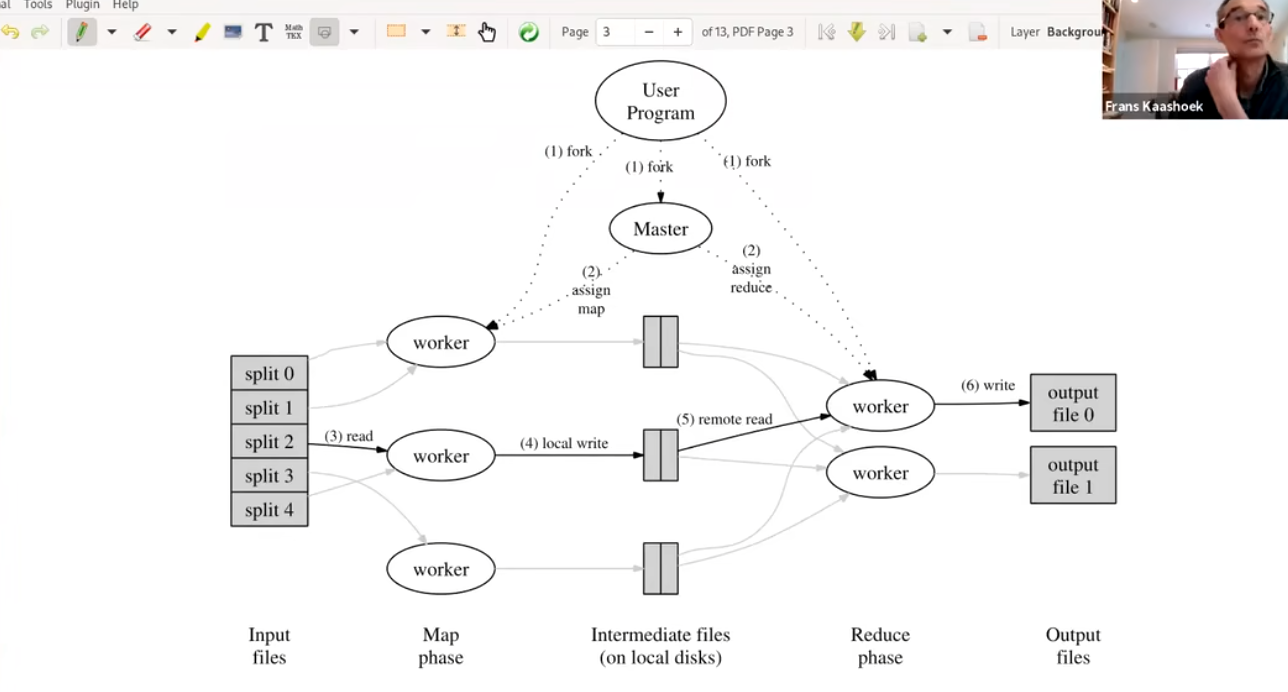
- 首先会创建许多worker,以及Master进程。其中一般来说Worker进程有两种一种是负责map任务一种是负责reduce任务(一个Worker会专注执行一种任务要么是reduce要么是map)。
- Master进程,又被称为协调器,负责任务(map,reduce任务)分配给不同的worker
- 当输入的数据到来的时候,会被分为M个小文件(每个文件大小大概是16M-64M),然后在集群中启动MapReduce实例,其中有一个Master和多个Worker
- Master会将小文件发给可用的Worker,这是基于GFS实现的,所以不存在网络传输
- Worker得到小文件后,会读取文件并对其进行map操作,输出key/value对(中间状态<a,1>,<b,1>,<a,1>),首先缓存在内存中,在内存上存储实际是一个循环数组,有两个指针,一个指向可读的位置,一个指向可写的位置,当这个数组到达一个阈值(80%)就会执行flush操作,将数据写入磁盘,在内存中已经写入的数据会被移除(移动可读指针)。再写入磁盘前内存中的 (key, value) 对通过 partitioning function() 例如 hash(key) mod R 分为 R 个 regions(这个Regions的个数与执行reduce函数的Worker有关)。写入磁盘后,把这些文件的地址回传给 Master,然后 Master 把这些位置传给 Reduce Worker;
- Reduce Worker 收到 Master 的位置信息后,会使用RPC从MapWorker所在的磁盘读取这些数据,并根据key进行排序,然后将同一key的所有数据聚合在一起(由于许多不同的 key 值会映射到相同的 Reduce 任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序);
- Reduce Worker 将分组后的值传给用户自定义的 reduce 函数,输出追加到所属分区的输出文件中;
- 当所有的 Map 任务和 Reduce 任务都完成后,Master 向用户程序返回结果;
输入文件在全局文件系统中,被称为GFS。Google现在使用的是不同的global file system,但该论文中使用的是GFS。
上面流程最后reduce输出结果会被保存到GFS,而map产生的中间文件不会被保存到GFS中(而是保存到worker运行的本地机器上)。

上图为流程的概要
问题1:在远程读取进程中,文件是否会传输到reducer?
回答1:是的。map函数产生的中间结果存放在执行map函数的worker机器的磁盘上,而之后解调器分配文件给reducer执行reduce函数时,中间结果数据需要通过网络传输到reducer机器上。这里其实很少有网络通信,因为一个worker在一台机器上,而每台机器同时运行着worker进程和GFS进程。worker运行map产生中间结果存储在本地,而之后协调器给worker分配文件以执行reduce函数时,才需要通过网络获取中间结果数据,最后reduce处理完在写入GFS,写入GFS的动作也往往需要通络传输。
问题2:协调器是否负责对数据进行分区,并将数据分发到每个worker或机器上?
回答2:不是的。mapreduce运行用户程序,这些输入数据在GFS中。(也就是说协调器告知worker从GFS取哪些数据进行map,后续协调器又告知worker从哪些worker机器上获取中间结果数据进行reduce,最后又统一写入到GFS中)
问题3:这里涉及的排序是如何工作的?比如谁负责排序,如何排序?
回答3:在中间结果数据传递到reduce函数之前,mapreduce库进行一些排序。比如所有的中间结果键a、b、c到一个worker。比如(a,1) (b,1) (c,1) (a,1) 数据,被排序成(a,1) (a,1) (b,1) (c,1) 后才传递给reduce函数。
问题4:很多函数式编程是否可以归结为mapreduce问题?
回答4:是的。因为map、reduce函数的概念,在函数式编程语言中非常常见,或者说函数式编程真是map、reduce的灵感来源。
mapreduce的容错性
-
主要分为两种故障:
- Worker故障:Master 周期性的 ping 每个 Worker,如果指定时间内没回应就是挂了。将这个 Worker 标记为失效,分配给这个失效 Worker 的任务将被重新分配给其他 空闲的Worker;这就是fault tolerance容错的基本方案
换句话说,如果coordinator没有收到worker反馈task任务完成,那么会coordinator重新分配worker要求执行task(可能分配到同一个worker,重点是task会被重新执行)。这里涉及一个问题,map是否会被执行两次?
或许没反馈task执行done完成的worker是遇到网络分区等问题,并没有宕机,或者协调者不能与worker达成网络通信,但实际上worker仍然在运行map任务,它正在产生中间结果。这里的答案是,同一个map可以被运行两次。
**被执行两次是能够接受的(幂等性问题),正是map和reduce属于函数式(functional)的原因之一。**如果map/reduce是一个funcitonal program,那么使用相同输入运行时,产生的输出会是相同的(也就是保证幂等)。
**类似的,reduce能够运行两次吗?**是的,和map出于相同的原因,从容错的角度上看,执行reduce函数和map函数并没有太大区别。**需要注意的是,这时候可能有两个reducer同时有相同的输出文件需要写入GFS,它们首先在全局文件系统GFS中产生一个中间文件,然后进行atomic rename原子重命名,将文件重命名为实际的最终名称。**因为在GFS中执行的重命名是原子操作,最后哪个reducer胜出并不重要,因为reduce是函数式的,它们最终输出的数据都是一样的。
- Master 故障:中止整个 MapReduce 运算,重新执行。一般很少出现 Master 故障。
问题1:一台机器应该可以执行多个map任务,如果它分配10个map任务,而在执行第7个map任务时失败了,master得知后,会安排将这7个已完成的map任务分布式地重新执行,可能分散到不同的map机器上,对吗?
回答1:是的。虽然我认为通常一台机器只运行一个map函数或一个reduce函数,而不是多个。
问题2:在worker完成map任务后,它是否会直接将文件写入其他机器可见的位置,或者只是将文件保存到自己的文件系统中?
回答2:map函数总是在本地磁盘产生结果,所以中间结果文件只会在本地文件系统中。
问题3:即使一次只做一个map任务,但是如果执行了多次map任务后,如果机器突然崩溃,那么会丢失之前负责的所有map任务所产生的中间结果文件,对吗?
回答3:不,中间结果文件放在本地文件系统中(磁盘中)。所以当机器恢复时,中间结果文件还在那里,因为文件数据是被持久化保存的,而不是只会存在于内存中(换句话说,这里依赖了操作系统的文件系统本身的容错性)。并且map或reduce会直接访问包含intermediate results中间结果的机器。
mapreduce其他异常场景
- 执行缓慢的worker(Slow workers)?
比如GFS也在同一台机器上运行占用大量的机器周期或带宽,或硬件本身问题,导致worker执行map/reduce很慢。慢的worker被称为straggler,当剩下几个map/reduce任务没有执行时,协调者会另外分配相同的map/reduce任务到其他闲置worker上运行,达到backup task的效果(因为函数式,map/reduce以相同输入执行最后会产生相同输出,所以执行多少次都不会有问题)。
通过备用任务(backup task),性能不会受限于最慢的几个worker,因为有更快的worker会领先它们完成task(map或reduce)。这是应对straggler的普遍做法,通过replicate tasks复制任务,获取更快完成task的输出结果,处理了tail latency尾部延迟问题。
结语
尽管由于一些原因,Google 已经不在使用 MapReduce 了。但 MapReduce 从根本上改变了大规模数据处理架构,它通过一个简单的 API,抽象了处理并行、容错和负载均衡的复杂性,让没有相关经验的程序员也能够在计算机集群上分布式地处理大规模数据集。
Threads和RPC(多线程和远程过程调用)
为什么选用go语言
这里主要讲为什么这个课程选用Go语言进行编程。
- good support for threads/RPC:对线程和RPC的支持度高
- gc:自带GC,无需考虑垃圾回收问题
- type safe:类型安全
- simple:简单易上手
- compiled:编译型语言,运行时开销更低
go的多协程挑战
-
race conditions:多线程会引入竞态条件的场景
- avoid sharing:避免共享内存以防止竞态条件场景的产生(Go有一个竞态检测器race detector,能够辅助识别代码中的一些竞态条件场景)
- use locks:让一系列指令变成原子操作
-
coordination:同步协调问题,比如一个线程的执行依赖另一个线程的执行结果等
- channels:通道允许同时通信和协调
- condition variables:配合互斥锁使用
-
deadlock:死锁问题,比如在go中简单的死锁场景,一个写线程往channel写数据,但是永远没有读线程从channel读数据,那么写线程被永久阻塞,即死锁,go会抓住这种场景,抛出运行时错误runtime error。
go如何应对多线程的挑战
- channels:通道
- no-sharing场景:如果线程间不需要共享内存(变量等),一般偏向于使用channels完成线程间的通信
- locks + condition variables:锁和条件变量配套使用
- shared-memory:如果线程间需要共享内存,则采用锁+条件变量的方案。比如键值对key-value服务,需要共享key-value table。
go的堆栈和逃逸分析
相比于把内存分配到堆中,分配到栈中优势更明显。Go语言也是这么做的:Go编译器会尽可能将变量分配到到栈上。但是,当编译器无法证明函数返回的变量有没有被引用时,编译器就必须在堆上分配该变量,以此避免悬挂指针(dangling pointer)的问题。另外,如果局部变量占用内存非常大,也会将其分配在堆上。
问题:go是如何确定内存是分配到栈上还是堆上?
答案:逃逸分析
逃逸分析
- 什么是逃逸分析:编译器通过逃逸分析技术去选择堆或者栈,逃逸分析的基本思想如下:检查变量的生命周期是否是完全可知的,如果通过检查,则在栈上分配。否则,就是所谓的逃逸,必须在堆上进行分配。
逃逸分析的基本原则
- 不同于JAVA JVM的运行时逃逸分析,Go的逃逸分析是在编译期完成的:编译期无法确定的参数类型必定放到堆中;
- 如果变量在函数外部存在引用,则必定放在堆中;
- 如果变量占用内存较大时,则优先放到堆中;
- 如果变量在函数外部没有引用,则优先放到栈中;
逃逸分析举例
我们使用这个命令来查看逃逸分析的结果: go build -gcflags ‘-m -m -l’
- 参数类型是interface类型
1 | pacakge main |
运行结果
这段代码就输出了 a escapes to heap
原因分析
因为Println的参数类型是interface,编译器无法确定它的具体类型,因此必须在堆上分配。
- 变量在外部存在引用
1 | package main |
运行结果
这段代码就输出了moved to head: a
原因分析
变量a在函数外部存在引用。
我们来分析一下执行过程:当函数执行完毕,对应的栈帧就被销毁,但是引用已经被返回到函数之外。如果这时外部通过引用地址取值,虽然地址还在,但是这块内存已经被释放回收了,这就是非法内存。
为了避免上述非法内存的情况,在这种情况下变量的内存分配必须分配到堆上
- 变量占用内存较大
1 | package main |
运行结果
这段代码就输出了make([]int, 10000, 10000) escapes to heap
原因分析
我们定义了一个容量为10000的int类型切片,发生了逃逸,内存分配到了堆上(heap)。
- 变量大小不确定的时候也会分配在堆上
1 | package main |
运行结果
这段代码就输出了make([]int, l, l) escapes to heap
原因分析
我们虽然在代码段中给变量 l 赋值了1,但是编译期间只能识别到初始化int类型切片时,传入的长度和容量是变量l,编译期并不能确定变量l的值,所以发生了逃逸,会把内存分配到堆中。
谷歌文件系统GFS
- 首先我们从三个方面去讨论:
- 从存储
- 介绍GFS
- 一致性
存储
- 存储的重要性:通常来说应用程序是无状态的,一些用户数据需要永久保存,这就需要存储,最简单的可以存储在本地磁盘上,再者可以存储在数据库中,
存储设计的难点
- 要考虑高性能
- 单个机器的网卡和CPU性能有限,所以需要考虑跨多个服务机器存储数据
- 因为要支持MapReduce,所以需要考虑分片
- 要考虑多机器下的容错
- 数几千台机器共同运行,总有几个会出现故障,所以需要考虑容错
- 通常通过复制数据保证容错性,即当前磁盘数据异常/缺失等情况,尝试从另一个磁盘获取数据
- 通过复制数据保证容错的话又会出现新问题:
- 会出现潜在的数据不一致问题,即多个副本之间数据不一致
- 那么就又引入了一致性问题
- 因此就需要一些一致性协议来保证数据一致性,一般需要通过一些消息机制保证一致性,这会稍微带来一些性能影响,但一般底层为了保证数据一致性而额外进行的网络通信等操作在整体性能的开销中占比并不会很高。其中可能涉及需要将通信的一些结果写入存储中,这是相对昂贵的操作。
一致性
**并发性(concurrency)和故障/失败(failures)**是两个实现一致性时需要考虑的难点。(WHY?)
-
并发性问题举例:
- W1写1,W2写2;R1和R2准备读取数据。W1和W2并发写,在不关心谁先谁后的情况下,考虑一致性,则我们希望R1和R2都读取到1或者都读取到2,R1和R2读取的值应该一致。(可通过分布式锁等机制解决)
-
故障/失败问题举例:
- 一般为了容错性,会通过复制的方式解决。而不成熟的复制操作,会导致读者在不做修改的情况下读取到两次不同的数据。比如,我们要求所有写者写数据时,需要往S1和S2都写一份。此时W1和W2并发地分别写1和2到S1、S2,而R1和R2即使在W1和W2都完成写数操作后,再从S1或S2读数时结果可能是1也可能是2(因为没有明确的协议指出这里W1和W2的数据在S1、S2上以什么方式存储,可能1被2覆盖,反之亦然)。
什么是GFS?
- GFS是一个可扩展的分布式文件系统,由Google开发,用于大规模集群环境中的海量数据存储和处理。
- GFS旨在保持高性能,且有复制、容错机制,但很难保持一致性
GFS的几个主要特征:
-
Big:large data set,巨大的数据集
-
Fast:automatic sharding,自动分片到多个磁盘
-
Gloal:all apps see same files,所有应用程序从GFS读取数据时看到相同的文件(一致性)
-
Fault tolerance:automic,尽可能自动地采取一些容错恢复操
GFS数据读取流程
-
GFS通过Master管理文件系统的元数据等信息,其他Client只能往GFS写入或读取数据。当应用通过GFS Client读取数据时,大致流程如下:
- Client向Master发起读数据请求
- Master查询需要读取的数据对应的目录等信息,汇总文件块访问句柄、这些文件块所在的服务器节点信息给Client(大文件通常被拆分成多个块Chunk存放到不同服务器上,单个Chunk(块)很大, 这里是64MB)
- Client得知需要读取的Chunk的信息后,直接和拥有这些Chunk的服务器网络通信传输Chunks
GFS-Master简述
-
Master主要负责的工作如下:
- 维护文件名到块句柄数组的映射(file name => chunk handles)(这些信息大多数存放在内存中,所以Master可以快速响应客户端Client)
- 维护每个块句柄(chunk handle)的版本(version)
- 维护块存储服务器列表(list of chunk servers)
- 主服务器(primary)
- Master还需维护每一个主服务器(primary)的租赁时间(lease time)
- 次要服务器(secondaries)
典型配置即将chunk存储到3台服务器上
- 主服务器(primary)
- log+check point:通过日志和检查点机制维护文件系统。所有变更操作会先在log中记录,后续才响应Client。这样即使Master崩溃/故障,重启时也能通过log恢复状态。master会定期创建自己状态的检查点,落到持久性存储上,重启/恢复状态时只需重放log中最后一个check point检查点之后的所有操作,所以恢复也很快
-
这里需要思考的是,哪些数据需要放到稳定的存储中(比如磁盘)?
- 比如file name => chunk hanles的映射,平时已经在内存中存储了,还有必要存在稳定的存储中吗?
答:需要,否则崩溃后恢复时,内存数据丢失,master无法索引某个具体的文件,相当于丢失了文件。 - chunk handle 到 存放chunk的服务器列表,这一层映射关系,master需要稳定存储吗?
答: 不需要,master重启时会要求其他存储chunk数据的服务器说明自己维护的chunk handles数据。这里master只需要内存中维护即可。同样的,主服务器(primary)、次要服务器(secondaries)、主服务器(primary)的租赁时间(lease time)也都只需要在内存中即可。 - chunk handle的version版本号信息呢,master需要稳定存储吗?
答:需要。否则master崩溃重启时,master无法区分哪些chunk server存储的chunk最新的。比如可能有服务器存储的chunk version是14,由于网络问题,该服务器还没有拿到最新version 15的数据,master必须能够区分哪些server有最新version的chunk。
- 比如file name => chunk hanles的映射,平时已经在内存中存储了,还有必要存在稳定的存储中吗?
问题:Master崩溃重启后,会连接所有的chunk server,找到最大的version?
回答:Master会尝试和所有chunk server通信,尽量获取最新version。当然有可能拥有最新version的chunk server由于网络等原因正好联系不上,此时能联系上的存活最久的chunk server的version会比master存储的version小。
GFS-文件读取
- Client向Master发请求,要求读取X文件的Y偏移量的数据
- Master回复Client,X文件Y偏移量相关的块句柄、块服务器列表、版本号(chunk handle, list of chunk servers, version
- Client 缓存cache块服务器列表(list of chunk servers)
- Client从最近的服务器请求chunk数据(reads from closest servers)
- 被Client访问的chunk server检查version,version正确则返回数据
-
为什么这里Client要缓存list of chunk server信息呢?
答:因为在这里的设计中,Master只有一台服务器,我们希望尽量减少Client和Server之间的通信次数,客户端缓存可以大大减少Master机器的负载。 -
为什么Client尽量访问最近的服务器来获取数据(reads from closest servers)?
答: 因为这样在宛如拓扑结构的网络中可以最大限度地减少网络流量(mininize network traffic),提高整体系统的吞吐量。 -
为什么在Client访问chunk server时,chunk server需要检查verison?
答: 为了尽量避免客户端读到过时数据的情况。
GFS-文件写入
这里主要关注文件写入中的append操作,因为把记录追加到文件中这个在他们的业务中很常见。在mapreduce中,reducer将处理后的记录数据(计算结果)很快地追加(append)到file中。
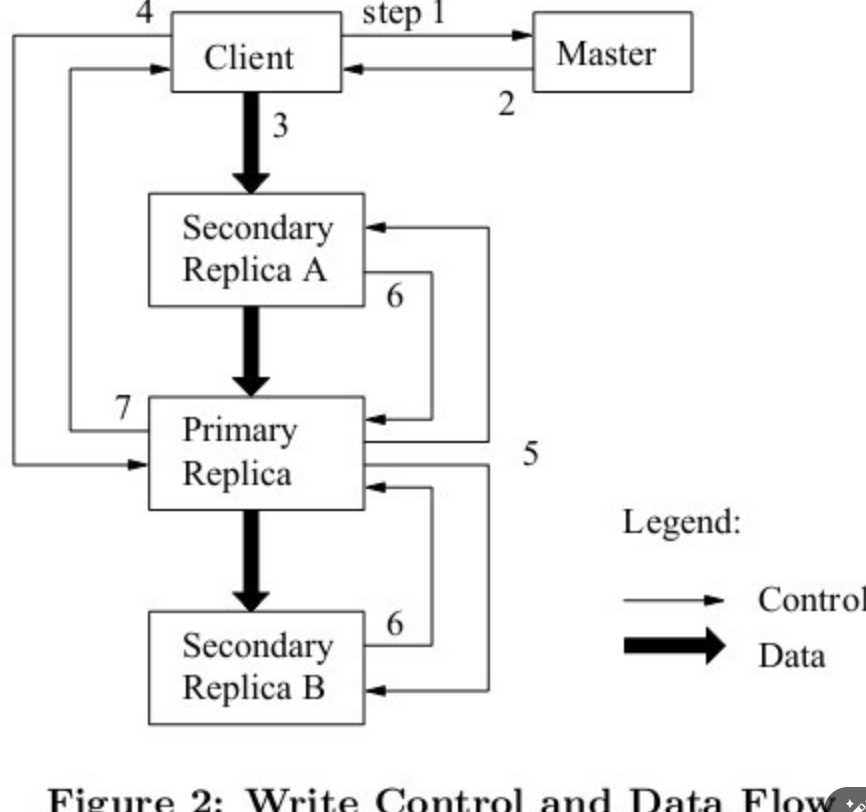
- Client向Master发出请求,查询应该往哪里写入filename对应的文件。
- Master查询filename到chunk handle映射关系的表,找到需要修改的chunk handle后,再查询chunk handle到chunk server数组映射关系的表,以list of chunk servers(primary、secondaries、version信息)作为Client请求的响应结果
接下去有两种情况,已有primary和没有primary(假设这是系统刚启动后不久,还没有primary)- 有primary: 继续后续流程
- 没有Primary:master在chunk servers中选出一个作为primary,其余的chunk server作为secondaries。(暂时不考虑选出的细节和步骤)
(master会增加version(每次有新的primary时,都需要考虑时进入了一个new epoch,所以需要维护新的version),然后向primary和secondaries发送新的version,并且会发给primary有效期限的租约lease。这里primary和secondaries需要将version存储到磁盘,否则重启后内存数据丢失,无法让master信服自己拥有最新version的数据(同理Master也是将version存储在磁盘中)。)
- Client发送数据到想写入的chunk servers(primary和secondaries),有趣的是,这里Client只需访问最近的secondary,而这个被访问的secondary会将数据也转发到列表中的下一个chunk server,此时数据还不会真正被chunk severs存储。(即上图中间黑色粗箭头,secondary收到数据后,马上将数据推送到其他本次需要写的chunk server),这么做提高了Client的吞吐量,避免Client本身需要消耗大量网络接口资源往primary和多个secondaries都发送数据。
- 数据传递完毕后,Client向primary发送一个message,表明本次为append操作
primary此时需要做几件事:- primary此时会检查version,如果version不匹配,那么Client的操作会被拒绝
- primary检查lease是否还有效,如果自己的lease无效了,则不再接受任何mutation operations(因为租约无效时,外部可能已经存在一个新的primary了)
- 如果version、lease都有效,那么primary会选择一个offset用于写入
- primary将前面接收到的数据写入稳定存储中
- primary发送消息到secondaries,表示需要将之前接收的数据写入指定的offset
- secondaries写入数据到primary指定的offset中,并回应primary已完成数据写入
- primary回应Client,你想append追加的数据已完成写入
当然,存在一些情况导致数据append失败,此时primary本身写入成功,但是后续存在某些/某个secondaries写入失败,此时会向Client返回错误error。Client遇到这种错误后,通常会retry整个流程直到数据成功append,这也就是所谓的最少一次语义(do at-least-once)
- 需要注意的是,假设append失败,Client再次重试,此时流程中primary指定写入的offset和上一次会是一样的吗?
不,primary会指定一个新的offset。假设primary+2台secondaries,可能上一次p和s1都写成功,仅s2失败。此时retry需要用新的offset,或许p、s1、s2就都写入成功了。这里可以看出来副本记录是可以重复的(replicates records can be duplicated),这和我们常见的操作系统中标准的文件系统不一样。
好在应用程序不需要直接和这种特殊的文件系统交互,而是通过库操作,库的内部实现隐藏了这些细节,用户不会看到曾经失败的副本记录数据。如果你append数据,库会给数据绑定一个id,如果库读取到相同id的数据,会跳过前面的一个。同时库内通过checksums检测数据的变化,同时保证数据不会被篡改。
主备复制
-
failures:复制失败场景和对策
-
challenge:实现难点
-
2 appliction:2个典型应用场景的探讨
- 状态转移复制(state transfer replication)
- 复制状态机(replicated state machines)
case study
-
VM FT:VMware fault tolerance
失败的场景
- 常见的复制失败场景分类
- fail-stop failure:基础设备或计算机组件问题,导致系统暂停工作(stop compute),一般指计算机原本工作正常,由于一些突发的因素暂时工作失败了,比如网线被切断等。
- logic bugs, configuration errors:本身复制的逻辑有问题,或者复制相关的主从配置有异常,这类failure导致的失败,不能靠系统自身自动修复。
- malicious errors:这里我们的设计假设的内部系统中每一部分都是可信的,所以我们无法处理试图伪造协议的恶意攻击者。
- handling stop failure:比如主集群突发地震无法正常服务,我们希望系统能自动切换到使用backup备份集群提供服务。当然如果主从集群都在一个数据中心,那么一旦出现机房被毁问题,大概率整个系统就无法提供服务了。
我们只关注处理停止失败(handling stop failures)。
主备复制的实现难点
-
为了防止出现脑裂的场景,我们该如何判断一个primary真正的失败了?
- 你无法直接区分发生了网络分区问题(network partition)还是实质的机器故障问题(machine failed)
- 或许只是部分机器访问不到primary,但是客户端还是正常和primary交互中。你必须有一些机制保证不会让系统同时出现两个primary(假设机制中只允许正常情况下有且只有一个primary工作)。
- (Split-brain system)脑裂场景
假设机制不完善,可能导致两个网络分区下各自有一个primary,客户端们和不同的primary交互,最后导致整个系统内部状态产生严重的分歧(比如存储的数据、数据的版本等差异巨大)。此时如果重启整个系统,我们就不得不手动处理这些复杂的分歧状态问题(就好似手动处理git merge冲突似的)。
-
如何让主备保持同步?
**我们的目标是primary失败时,backup能接手primary的工作,并且从primary停止的地方继续工作。这要求backup总是能拿到primary最新写入的数据,保持最新版本。**我们不希望直接向客户端返回错误或者无法响应请求,因为从客户端角度来看,primary和backup无区别,backup就是为容错而生,理应也能正常为自己提供服务。
-
需要保证应用中的所有变更,按照正确顺序被处理(apply changes in order)
-
必须避免/解决非决定论(avoid non-determinism)。即相同的变更在primary和backup上应该有一致的表现。
-
故障转移
primary出现问题时,我们希望切换到backup提供服务。但是切换之前,我们需要保证primary已经完成了所有正在执行的工作。即我们不希望在primary仍然在响应client时突然切换backup(如果遇到网络分区等问题,会使得故障转移难上加难)。
在计算机术语中,故障转移(英语:failover),即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作。 故障转移 (failover)与交换转移操作基本相同,只是故障转移通常是自动完成的,没有警告提醒手动完成,而交换转移需要手动进行。
主备复制的两种方法
-
状态转移(state transfer):primary正常和client交互,每次响应client之前,先生成记录checkpoint检查点,将checkpoint同步到备份backup,待backup都同步完状态后,primary再响应client。(即将主的最新消息同步到备份后,再响应client)
-
复制状态机(replicated state machine,RSM):与状态转移类似,只是这里primary和backup之间同步的不是状态,而是操作。即primary正常和client交互,每次响应client之前,先生成操作记录operations,将operations同步到备份backup,待backup都执行完相同的操作后,primary再响应client。
这两种方案都有被应用,共同的要点在于,primary响应client之前,首先确保和backup同步到相同的状态,然后再响应client。这样当primary故障时,任意backup接管都能有和原primary对齐的状态。
这两者的主要区别是方法一是执行完操作后,得到了结果,把结果同步到备份机上,而方法二则是将要执行的操作同步到备份机上,让备份机自己运行操作,并得到结果。
从这就能看出方法一的缺点了,如果一个操作得到了非常大的结果,那么同步起来就非常昂贵了
问题1:为什么client不需要发送数据到backup备机?
答1:因为这里client发送的请求是具有确定性的操作,只需向primary请求就够了。主备复制机制保证primary能够将具有确定性的操作正确同步到其他backup,即系统内部自动保证了primary和backup之间的一致性,不需要client额外干预。接下来的问题即,怎么确定一个操作是否具有确定性?在复制状态机(replicated state machine,RSM)方案中,即要求所有的操作都是具有确定性的,不允许存在非确定性的操作。
问题2:是不是存在着混合的机制,即混用状态转移(state transfer)和复制状态机(replicated state machine,RSM)?
答2: 是的。比如有的混合机制在默认情况下以复制状态机(replicated state machine,RSM)方案工作,而当集群内primary或backup故障,为此创建一个新的replica时则采用状态转移(state transfer)转移/复制现有副本的状态。
复制状态机RSM-复制什么级别的操作
使用复制状态机时,我们需要考虑什么级别的操作需要被复制。有以下几种可能性:
- 应用程序级别的操作(application-level operations)
比如GFS的文件append或write。如果你在应用程序级别的操作上使用复制状态机,那也意味着你的复制状态机实现内部需要密切关注应用程序的操作细节,比如GFS的append、write操作发生时,复制状态机应该如何处理这些操作。一般而言你需要修改应用程序本身,以执行或作为复制状态机方法的一部分。
- 机器层面的操作(machine-level operaitons),或者说processor level / coputer level
这里对应的状态state是寄存器的状态、内存的状态,操作operation则是传统的计算机指令。这种级别下,复制状态机无感知应用程序和操作系统,只感知最底层的机器指令。
有一种传统的进行机器级别复制的方式,比如你可以额外购买机器/处理器,这些硬件本身支持复制/备份,但是这么做很昂贵。
这里讨论的论文(VM-FM论文)通过虚拟机(virtual machine, VM)实现。
通过虚拟化实现复制
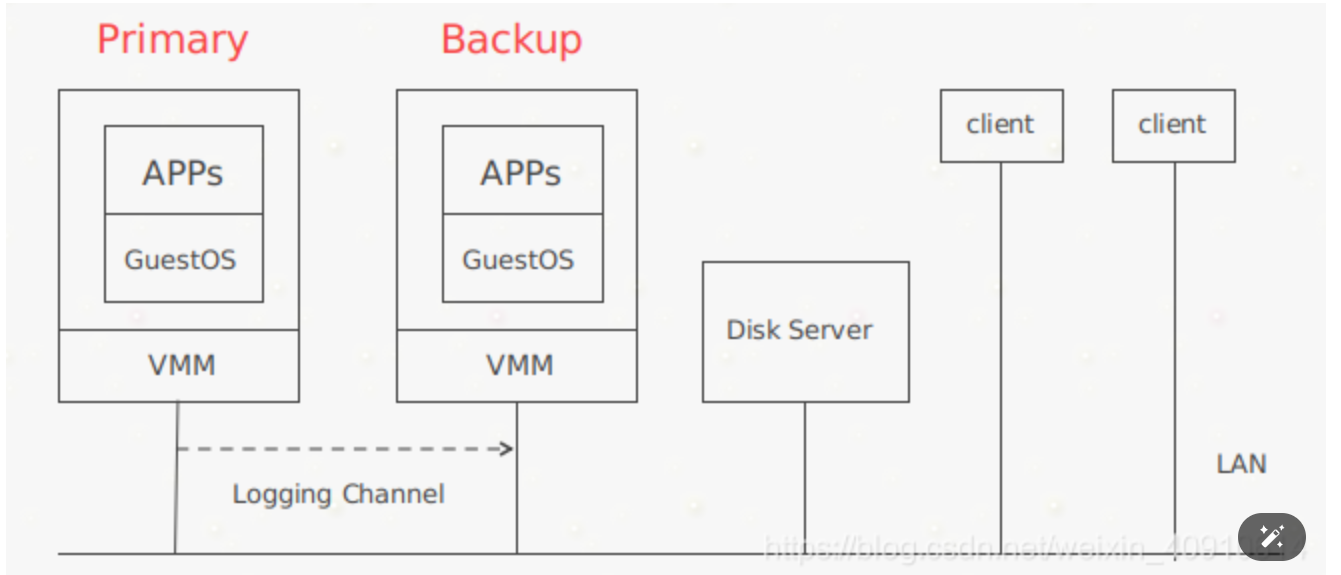
-
虚拟化复制对应用程序透明,且能够提供很强的一致性。早期的VMware就是以此实现的,尽管现在新版可能有所不同。缺陷就是这篇论文只支持单核,不支持多核(multi-core)。或许后来的FT支持了,但应该不是纯粹通过复制状态机实现的,或许是通过状体转移实现的,这些都只是猜测,毕竟VMware没有透露后续产品的技术细节。
-
我们先简单概览一下这个系统实现。
-
首先有一个虚拟机控制器(virtual machine monitor),或者有时也被称为hypervisor,在这论文中,对应的hypervisor即VM-FT。
-
当发生中断(比如定时器中断)时,作为hypervisor的VM-FT会接收到中断信号,此时它会做两件事:
- 通过日志通道将中断信号发送给备份计算机(sends it over a logging channel to a backup computer)
- 将中断信号传递到实际的虚拟机,比如运行在guest space的Linux。
-
同理,当client向primary发送网络数据包packet时,primary所在的硬件产生中断,而VM-FT将同样的中断通过logging channel发送给backup computer(也就是另一个VM-FT),然后将中断发送到当前VM-FT上的虚拟机(比如Linux)。另一台backup的VM-FT上运行着和priamry相同的Linux虚拟机,其也会同样收到来自backup的VM-FT的中断信号。primary虚拟机Linux之后往虚拟网卡写数据,产生中断,同样VM-FT也会将中断往backup的VM-FT发送一份。最后就是primary上的Linux虚拟机和backup上的Linux虚拟机都往各自的虚拟网卡发送了数据,但是backup的VM-FT知道自己是backup备机,所以从虚拟网卡接收数据后什么也不会做,只有primary的VM-FT会真正往物理网卡写数据,响应client的请求。
-
论文中提到,在primary和backup两个VM-FT以外,假设还通过网络和外部一个storage存储保持通讯。外部storage通过一个flag记录primary和backup状态,记录谁是primary等信息。这个存储有两个作用:
- 首先他能够进行数据的存储
- 第二它能够在一定程度上防止脑裂的发生,因为它有一个flag标志,并且使用了testandset原理来保证flag的修改。
-
当primary和backup之间发生网络分区问题,而primary、backup仍可以与这个外部storage通信时,primary和backup互相会认为对方宕机了,都想把自己当作新的primary为外界的client提供服务。此时,原primary和原backup都试图通过test-and-set原子操作在外部storage修改flag记录(比如由0改成1之类的),谁先完成修改修改,谁就被外部storage认定为新的primary;而后来者test-and-set操作会返回1(test-and-set会返回旧值,这里返回1而不是0,表示已经有人领先自己把0改成1了),其得知自己是后来者,会主动放弃称为primary的机会,在论文中提到会选择终结自己(terminate itself)。
test-and-set的伪代码如下:
1 | test-and-set(): |
- 虚拟机primary和backup都可能会失效,所以为了架构的高可用性,VMWare提出了一个技术FT VMotion,用来负责backup的创建。它能够直接对一个VM进行克隆,并且在完成克隆后会建立好和primary的Logging channel,被克隆一方是primary,另一个就是backup。根据协议,当backup启动完成备份时,flag就被重置为0。
差异来源
-
如果前面primary执行的指令都是确定性的,那么primary和backup无疑可以保证拥有相同的状态。但是不可避免的是可能出现一些非确定性的事件,我们需要考虑如何处理。我们的目标即,将每一条非确定性的指令(non-deterministic instruction)变成确定性指令(deterministic instruction)。
-
非确定性的指令(non-deterministic instruction)
- 比如获取时间的指令,我们不可能保证primary和backup都在同一时间执行,返回值一般来说会不同。
-
网络包接收/时钟中断(input packets / timer interrupters)
- 比如网络包输入时导致中断,primary和backup在原本CPU执行流中插入中断处理的位置可能不同。比如primary在第1~2条指令执行的位置插入网络包的中断处理,而backup在第2~3条指令执行的位置插入中断处理,这也有可能导致后续primary和backup的状态不一致。所以我们希望这里数据包产生的中断(或者时钟中断),在primary和backup相同的CPU指令流位置插入执行中断处理,确保不会产生不一致的状态。
那么它是怎么将非确定事件变为确定性事件的呢?
答:解决这个问题是利用了日志。primary的所有确定性操作和不确定事件的所有状态都会记录在log entry流中,通过Logging channel发送给backup并使其replay。
举个例子,一个操作让 primary 生成一个随机数,那么 primary 会在日志中记录当前生成这个操作的所有状态,比如它是根据当前时间或者是当前某个时钟周期当作 seed,这些随机性全部由 hypervisor 来处理,backup 进行日志 replay 时,碰到这种随机性事件,hypervisor 让它执行的时候跟 primary 得出的结果一模一样,让两者在状态上没有差别,很了不起。
VM-FT的中断处理
根据前面的讨论,可以知道中断是一个非确定性的差异来源,我们需要有机制保证primary和backup处理中断后仍保持状态一致。
这里VM-FT是这样处理的,当接受到中断时,VM-FT能知道CPU已经执行了多少指令(比如执行了100条指令),并且计算一个位置(比如100),告知backup之后在指令执行到第100条的时候,执行中断处理程序。大多数处理器(比如x86)支持在执行到第X条指令后停止,然后将控制权返还给操作系统(这里即虚拟机监视器)。
通过上面的流程,VM-FT能保证primary和backup按照相同的指令流顺序执行。当然,这里backup会落后一条message(因为primary总是领先backup执行完需要在logging channel上传递的消息)。
VM-FT失败场景的处理
这里举例primary故障的场景:
比如primary本来维护一个计数器为10,client请求将其自增到11,但是primary内部自增了计数器到11,但是响应client前正好故障了。如果backup此时接手,其执行完logging channel里要求同步的指令,但是自增到11这个并没有反映到bakcup上。如果client再次请求自增计数器,其会获取到11而不是12。

- 上述场景实际上不会发生,因为VM-FT定义了一个Output Rule。
- 为了保证上述要求,设计输出规则(如上图):
- primary在所有关于本次Output的信息都发送给backup后(并且要确保backup收到,backup会发送一个ACK),才会把output发送给外界。
- primary只是推迟将output发送给外界,不会暂停执行后面的任务(异步执行)。
如图,简单来说,就是primary收到一条信息,并且这条信息是需要回复的(即,要output),那么primary先会写日志并且传给backup,backup收到以后发送一个确认收到的ACK给primary,然后primary才会执行output。
- 但是,这种方法不能保证Exactly once(只发送一次),因为若primary在收到backup的ACK之后,已经发出了output,但是此时挂掉了,然后backup顶上去之后不能判断是否是在发送了output之后宕机的,所以它会再发一次。这个问题容易解决:
- output是通过网络进行发送的,例如TCP之类的网络协议能够检测重复的数据包;
- 对于一个写操作,它就是两次在同一个位置写,也不影响结果。
VM-FT性能问题
因为VM-FT的操作都基于机器指令或中断的级别上,所以需要牺牲一定的性能。
论文中统计在primary/backup模式下运行时,性能和平时单机差异不会太大,保持在0.94~0.98的水平。而当网络输入输出流量很高时,性能下降很明显,下降将近30%。这里导致性能下降的原因可能是,primary处理大量数据包时,需要等待backup也处理完毕。
问题:如果primary宕机了几分钟,backup重新创建一个replica并通过test-and-set将storage的flag从0设置为1,自己成为新的primary。然后原primary又恢复了,这时候会怎么样?
回答:原primary会被clean,terminate自己。
问题:处理大量网络数据包时,primary只会等待backup确认第一个数据包吗?
回答:不是,primary每处理一个数据包,都会通过logging channel同步到backup,并且等待backup返回ack。满足了输出规则(output rule)之后,primary才会发出响应。这里它们有一些方法让这个过程尽量快。
问题:关于logging channel,我看论文中提到用UDP(发送心跳会用这个)。那如果出现故障,某个packet没有被确认,primary是不是直接认为backup失败,然后不会有任何重播?
回答:不是。因为有定时器中断,定时器中断大概每10ms左右触发一次。如果有包接受失败,primary会在心跳中断处理时尝试重发几次给backup,如果等待了可能几秒了还是有问题,那么可能直接stop停止工作。
错误容忍-Raft算法
单点故障
前面介绍过的复制系统,都存在单点故障问题(single point of failure)。
- mapreduce中的cordinator
- GFS的master
- VM-FT的test-and-set存储服务器storage
而上诉的方案中,采用单机管理而不是采用多实例/多机器的原因,是为了避免**脑裂(split-brain)**问题。
不过大多数情况下,单点故障是可以接受的,因为单机故障率显著比多机出现一台故障的概率低,并且重启单机以恢复工作的成本也相对较低,只需要容忍一小段时间的重启恢复工作。
脑裂问题
- 定义:是指在分布式系统中,由于网络分区或其他故障导致集群中的节点无法相互通信,进而形成多个独立的子集(通常是两个),每个子集都认为自己是唯一的集群。 这种情况可能导致数据的不一致性、系统的不可用性和其他严重问题
Raft是避免单点故障问题的一种方案,在介绍Raft之前,我们要知道单机管理的某些协议在多机下是如何产生脑裂问题的,体会下为什么必须需要比这些协议更加严谨的协议
以VM-FT的test-and-set存储服务器storage举例。假设我们复制storage服务器,使其有两个实例机器S1、S2。(即打破单机管理的场景,看看简单的多机管理下有什么问题)
假设此时C1想要争取称为Primary,于是向S1和S2都发起test-and-set请求。假设因为某种原因,S2没有响应,S1响应,成功将0改成1,此时C1可能直接认为自己成为Primary。
这里S2没有响应可以先简单分析两种可能:
-
S2失败/宕机了,对所有请求方都无法提供服务
如果是这种情况,那么C1成为Primary不会有任何问题,S2就如同从来不曾存在,任何其他C同样只能访问到S1,他们都会知道自己无法成为Primary,并且整个系统只会存在C1作为Primary。 -
S2和C1之间产生了网络分区(network partition),仅C1无法访问到S2
这时候如果存在C2也向S1和S2发出请求,此时S1虽然将0改成1会失败,但是S2会成功。如果我们的协议不够严谨,这里C2会认为自己成为了Primary,导致整个系统存在两个Primary。这也就是严重的脑裂问题。
- 产生这种问题的原因在于,对于请求方,无法简单地判断上诉两种情况,因为对他们来说两种情况的表现都是一样的。
因此,为避免出现脑裂,我们需要先解决网络分区问题。
Raft采取的的原则:大多数原则
诸如Raft一类的协议用于解决单点故障问题,同时也用于解决网络分区问题。这类解决方案的基本思想即:大多数原则(majority rule),简单理解就是少数服从多数(获取票数多于一半)。
为什么这个原则会作为基本思想
- 我们来看看这个原则可以解决一些什么问题
就那我们上一个举例来扩展,我们假设storage服务一共有三个实例,S1、S2、S3。
此时C1同时向S1、S2、S3请求test-and-set,其中S1和S2成功将0改成1,S3因为其他问题没有响应,但是我们不关系为什么。这里按照majority rule,只要3个S中有2个给出成功响应,我们就认为C1能够成为Primary。此时就算同时有C2向S1、S2、S3发起请求,就算S3成功了,C2根据majorty rule,3台只成功1台,不能成为Primary。
这样就解决了脑裂问题,因为只有C1能够成为Primary,而C2只能访问到S1,S2。
在之后准备介绍的Raft,和这里描述的工作流程基本一致。
- 在majority rule下,尽管发生网络分区,只会一个拥有多数的分区,不会有其他分区具有多数,只有拥有多数的分区能继续工作(比如这里3台被拆成1台、2台的分区,只有和后者成功通信的能继续工作)。
- 而如果极端情况下所有分区都不占多数( 比如这里3台被拆成1台、1台、1台的分区),那么整个系统都不能运行。
上诉3台的场景,只能容忍1台宕机,如果宕机2台,那么任何人都无法达到majorty的情况。这里通过2f+1拓展可容忍宕机的机器数,f表示可容忍宕机的机器数量。2f+1,即使宕机了f台,剩下的f+1>f,仍然可以组成majority完成服务。
例如,当f=2时,表示系统内最多可容忍2台机器处于宕机状态,那么至少需要部署5台服务器(2x2+1=5)。
raft历史发展
-
在1980s~1990s,基本不存在诸如majority的协议,所以一直存在单点故障的问题。
-
在1990s出现了两种被广泛讨论协议,但是由于当时的应用没有自动化容错的需求,所以基本没有被应用。但近15年来(2000s~2020s)大量商用产品使用到这些协议:
- Paxos
- View-Stamped replication (也被称为VR)
附上Paxos算法的相关讲解文章: Paxos算法详解
- 我们将要讨论的是Raft,大概在2014左右有相关的论文,它应用广泛,你可以用它来实现一个完全复制状态机(complete replicated state machine)。
使用Raft构造复制状态机
系统正常工作时,大致流程如下:
- Client向3台机器中作为leader的机器发查询请求
- leader机器将接收到的请求记录到底层raft的顺序log中
- 当前leader的raft将顺序log中尾部新增的log记录通过网络同步到其他2台机器
- 其他两台K/V机器的raft成功追加log记录到自己的顺序log中后,回应leader一个ACK
- leader的raft得知其他机器成功将log存储到各自的storage后,将log操作反映给自己的K/V应用,执行这个操请求,并且设为了提交状态
- K/V应用实际进行K/V查询,并且将结果响应给Client,之后就会通知其他群众提交状态,以保持同步
系统出现异常时,发生如下事件:
- Client向leader请求
- leader向其他2台机器同步log并且获得ACK
- leader准备响应时突然宕机,无法响应Client
- 其他2台机器重新选举出其中1台作为新的leader
- Client请求超时或失败,重新发起请求,系统内部failover故障转移,所以这次Client请求到的是新leader
- 新leader同样记录log并且同步log到另一台机器获取到ACK
- 新leader响应Client
这里可以想到的是,剩下存活的两台机器的log中会有重复请求,而我们需要能够检测(detect)出这些重复请求。
问题:访问leader的client数量通常是多少?
回答:我想你的疑问是系统只有1个leader的话,那能承受多少请求量。实际上,具体的系统设计还会采用shard将数据分片到多个raft实例上,每个shard可以再有各自的leader,这样就可以平均请求的负载到其他机器上了。
问题:旧leader宕机后,client怎么知道要和新leader通信?
回答:client中有系统中所有服务器的访问列表,这里举例中有3个服务器。当其中一台请求失败时,client会重新随机请求3台中的1台,直到请求成功。
Raft概述
首先我们要知道Raft的几个重要角色:
- Leader:Raft协议中,每个副本(replica)都有可能成为Leader,Leader负责处理客户端的请求,并将其转发给其他副本。Leader在Raft中扮演着重要的角色,它负责将客户端请求转发给其他副本,并在必要时进行日志的复制。
- Candidate:Raft协议中,当Leader出现故障时,会选举出一个新的Leader。在Raft中,Candidate扮演着重要的角色,它会向其他副本发送请求,询问是否可以成为新的Leader。
- Follower:Raft协议中,Follower是Raft中最基本的角色,它只负责接收Leader的日志,并将其提交到自己的存储中。Follower在Raft中扮演着重要的角色,它负责接收Leader的日志,并将其提交到自己的存储中。
然后在进行选举过程中,还有几个重要的概念:
- Leader Election(领导人选举):简称选举,就是从候选人中选出领袖;
- Term(任期):它其实是个单独递增的连续数字,每一次任期就会重新发起一次领导人选举;
- Election Timeout(选举超时):就是一个超时时间,当群众超时未收到领袖的心跳时,会重新进行选举。
接下来我们重新描述下Raft的工作流程(此时已经有一个leader,另外两台为follower):
- 客户端向Leader发送请求;
- Leader将请求记录到log尾部,并将其转发给其他的fllower;
- Follower接收到Leader的请求后,将其记录到自己的log中,然后会回复Leader一个ACK;
- 此时leader和follower1共2台机器成功追加log,达到majority(必须符合大多数原则),于是leader可以进行commit,将操作移交给上层的kv服务。(这里即使宕机了一台,之后重新选举,包含最后操作的服务器将当选成为新的leader,比如原leader或follower1将当选,所以服务能继续正常提供)
- leader将log提交到自己的存储中commit后响应Client,完成一次请求,并且会发请求给所有的follower,让他们也进行commit。
问题:如果log从leader同步到其他follower时,leader宕机了,会怎么样?
回答:会重新发生选举,而拥有最新操作log的机器成为新leader后会将追加的log条目传递给其他follower,这样就保证这些机器都拥有最新的log了
Raft log的用途
- 重传:leader向follower同步消息时,消息可能传递失败,所以需要log记录,方便重传
- 顺序执行: 我们需要被同步的操作,以相同的顺序出现在所有的replica上
- 持久化(persistence):持久化log数据,才能支持失败重传,重启后日志恢复等机制
- 试探性操作(space tentative):比如follower接收到来自leader的log后,并不知道哪些操作被leader提交了,可能等待一会直到明确操作被commit了才进行后续操作。我们需要一些空间来做这些试探性操作(tentative operations),而log很合适。
尽管中间有些时间点,可能有些机器的log是落后的。但是当一段时间没有新log产生时,最终这些机器的log会同步到完全相同的状态(logs identical on all servers)。并且因为这些log是有顺序的,意味着上层的kv服务最终也会达到相同的状态。
Raft的log格式
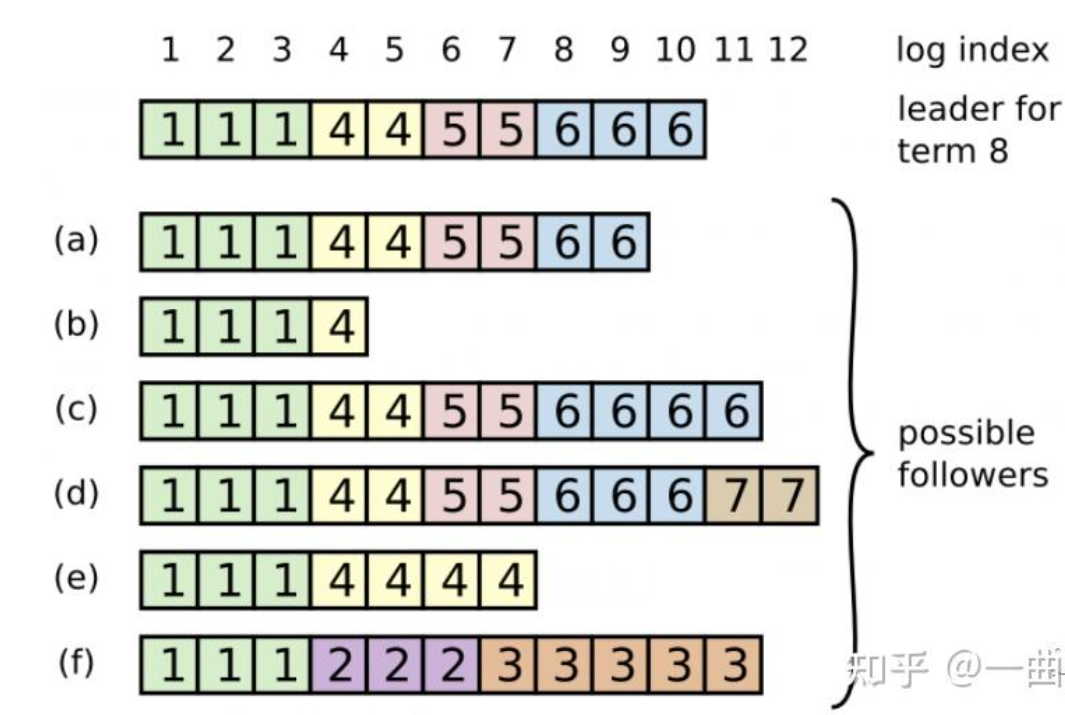
每一个日志条目一般包括三个属性:整数索引Log Index、任期号Term和指令Commond。每个条目所包含的“整数索引”即该条目在日志文件中的槽位,“任期号”对应到图中就是每个方块中的数字,用于检测在不同服务器上日志的不一致问题,指令即用于被状态机执行的外部命令,图中就是带箭头的数字。
Raft的选举
情况1 :集群中没有leader
我们假设一共有五个节点,每个节点的初始状态都是follower,它们都有着不同的超时时间,terms技术为1
Raft的选举过程如下:
- 首先,等待一段时间,直至五个节点有一个节点超时了,然后超时的节点会变成candidate,并投自己一票,再向其他节点发送投票请求,并且会执行terms + 1;
- 由于此时只有一个候选人,所以其他节点都选了赞成票,票数大于集群个数的一半,于是候选节点变成了leader
- 成为leader后会不断向follower发送心跳
情况2 :集群中有leader,并且leader宕机了
此时只有一个节点变味了候选节点
- 其他follower由于没有收到leader的心跳,会一直等待,知道自己的超时时间超时,于是超时的节点就会成为候选人,发起新一轮竞选
- 后续操作和情况一类似就不赘述了
有两个候选人同时竞选(选举条件)
follower投给哪个候选人取决于Term(任期)更高的人,如果任期相同就会投给日志最新的人,如果日志都相同了,就先到先得
- 未出现投票分裂
- 两个候选人都会先给自己投一票,然后向其他节点发送投票请求(即使接受节点宕机),并且会执行terms + 1;
- 候选人之间会互投反对票,follower会根据一个上述规则投给一个候选人
- 其中一位候选人得到了超过半数的票,成为leader,并开始不断向follower发送心跳
- 出现投票分裂
- 两个候选人都会先给自己投一票,然后向其他节点发送投票请求(即使接受节点宕机),并且会执行terms + 1;
- 候选人之间会互投反对票,follower会根据一个上述规则投给一个候选人
- 此时假设票数相同都为两票,就出现了投票分裂
- 又可以分为两种情况:
- 假设此时另外一个follower先超时,将term + 1,由于这个新term大于其他两个候选人的term,所以其他候选人会给他投赞成票,于是他就成为leader
- 假设此时两个候选人同时超时,又会发送新一轮选举,然后继续循环等待,(为了避免这个情况,Raft在设计时会将选举超时时间设为一个随机值(150ms到300ms之间),避免所有节点同时超时,先到的也会先获得赞成票),直至打破循环
- 新leader开始不断向follower发送心跳
Raft的选举超时时间
选举超时的时间,应该设置成大概多少才合适?
- 略大于心跳时间(>= few heartbeats)
如果选举超时比心跳还短,那么系统将频繁发起选举,而选举期间系统对外呈现的是阻塞请求,不能正常响应client。因为election时很可能丢失同步的log,一直频繁地更新term,不接受旧leader的log(旧leader的term低于新term,同步log消息会被拒绝)
- 加入一些随机数(random value)
加入适当范围的随机数,能够避免无限循环下去的分裂选举(split vote)问题。random value越大,越能够减少进行split vote的次数,但random value越大,也意味着对于client来说,整个系统停止提供对外服务的时间越长(对外表现和宕机差不多,反正选举期间无法正常响应client的请求)
- 尽量短(short enough that down time is short)
因为选举期间,对外client表现上如同宕机一般,无法正常响应请求,所以我们希望eleciton timeout能够尽量短
Raft论文进行了大量实验,以得到250ms~300ms这个在它们系统中的合理值作为eleciton timeout。
Raft-vote需记录到稳定的storage(持久化)
- 这里提一个选举中的细节问题。假设还是leader宕机,follower1和follower2中的follower1发起选举。follower1会先vote自己,然后发起拉票请求希望follower2投票自己。
- 这里follower1应该用一个稳定的storage记录自己的vote历史记录,有人知道为什么吗?原因是避免重复vote。假设follower1在vote自己后宕机一小段时间后恢复,我们需要避免follower1又vote自己一次,不然follower1由于vote过自己两次,直接就可以无视其他follower的投票认为自己成为了leader。
所以,为了保证每个term,每个机器只会进行一次vote行为,以保证最后只会产生一个leader,每个参选者都需要用稳定的storage记录自己的vote行为。
问题:这里需要记录vote之前当前机器自身是follower、leader或者candidate吗?
答:需要
Raft-日志
首先说明下集中图形代表啥:
- 虚线代表日志未提交

- 箭头代表下一索引,圆圈代表日志提交成功的索引下标


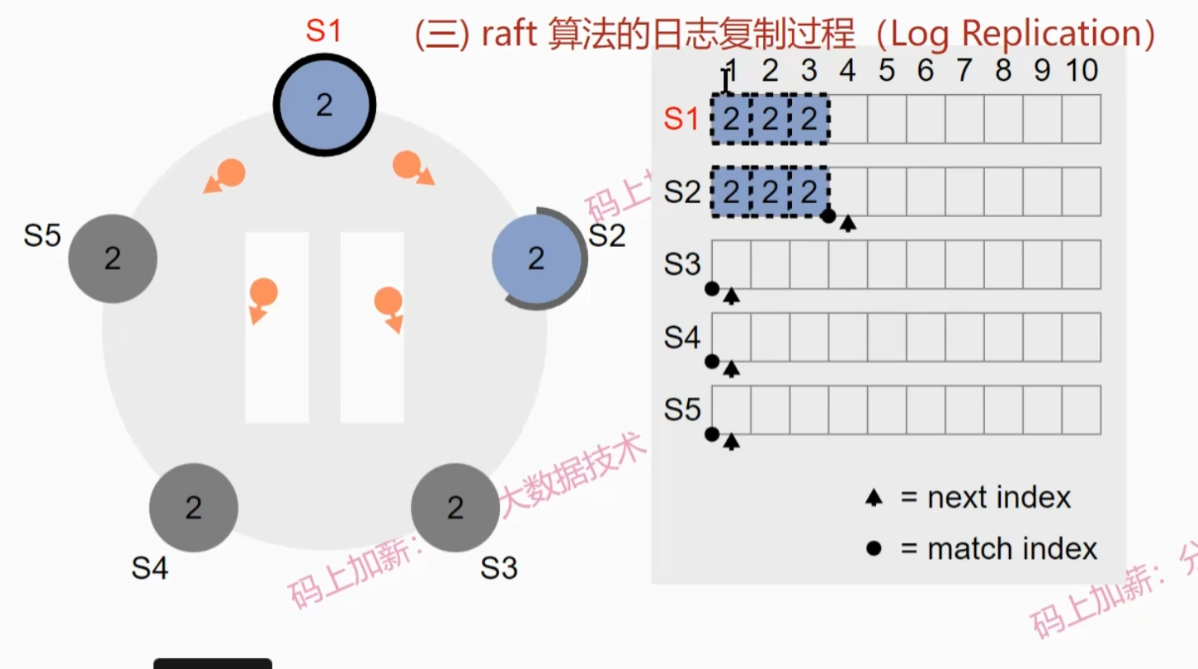
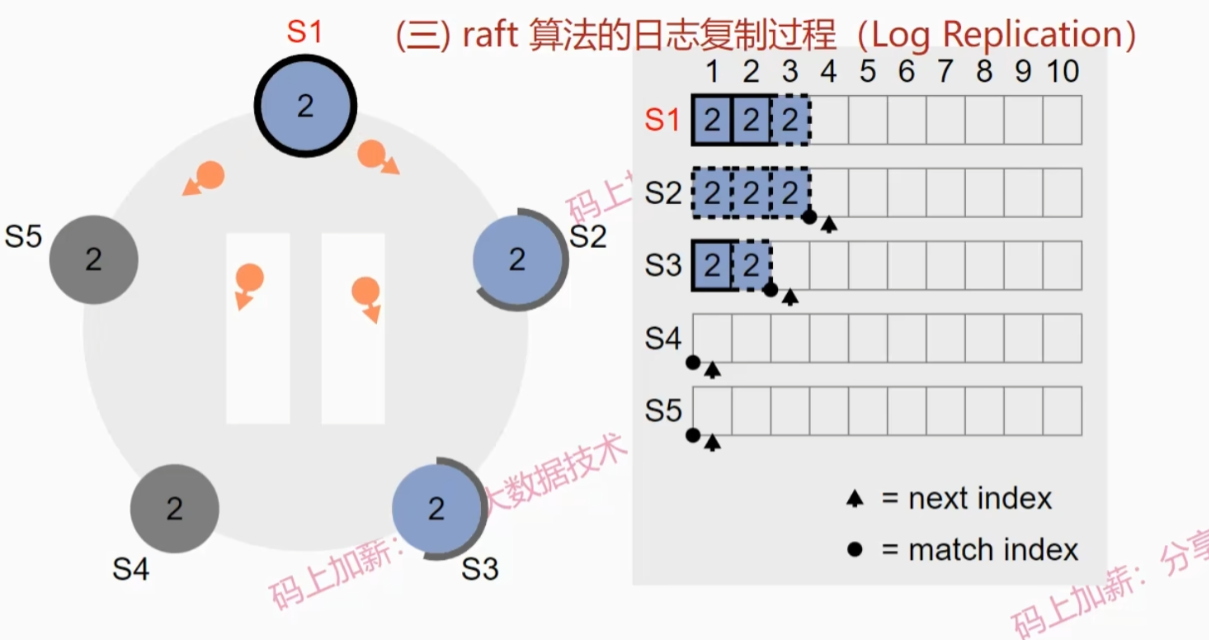
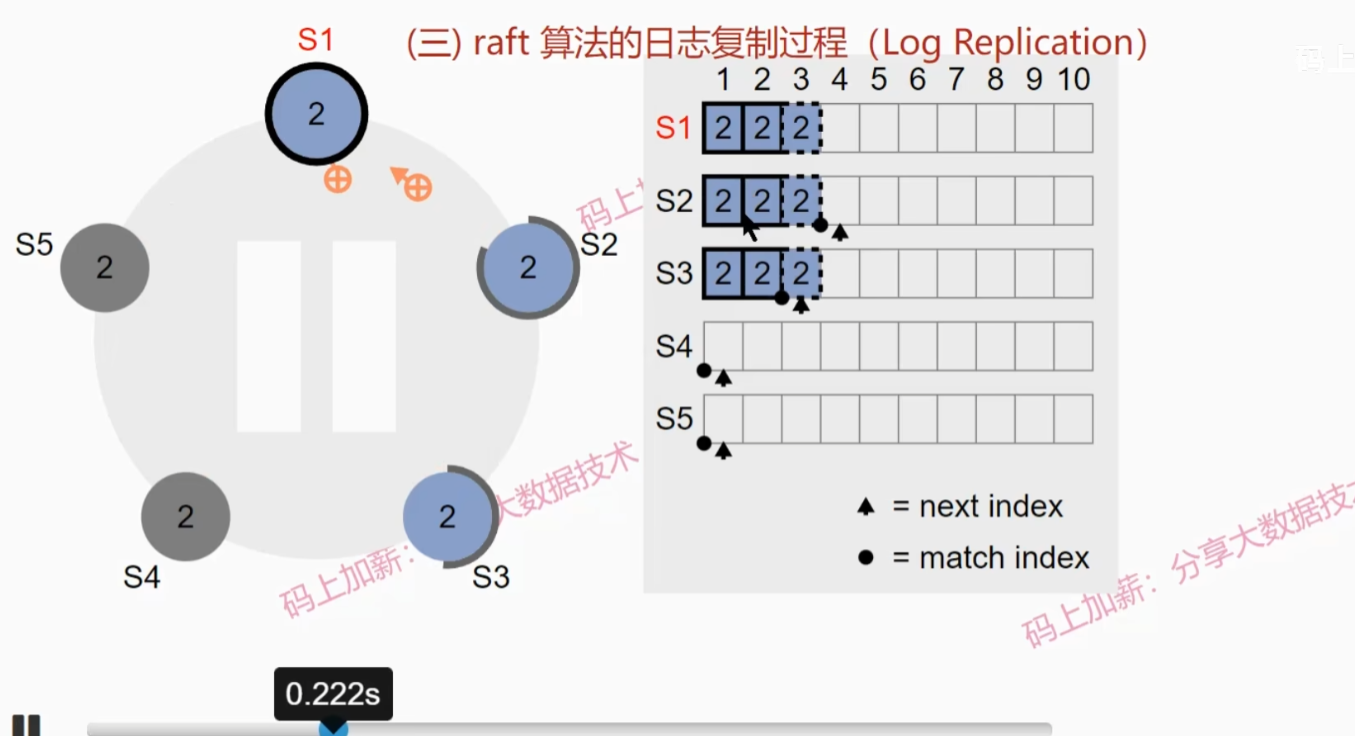
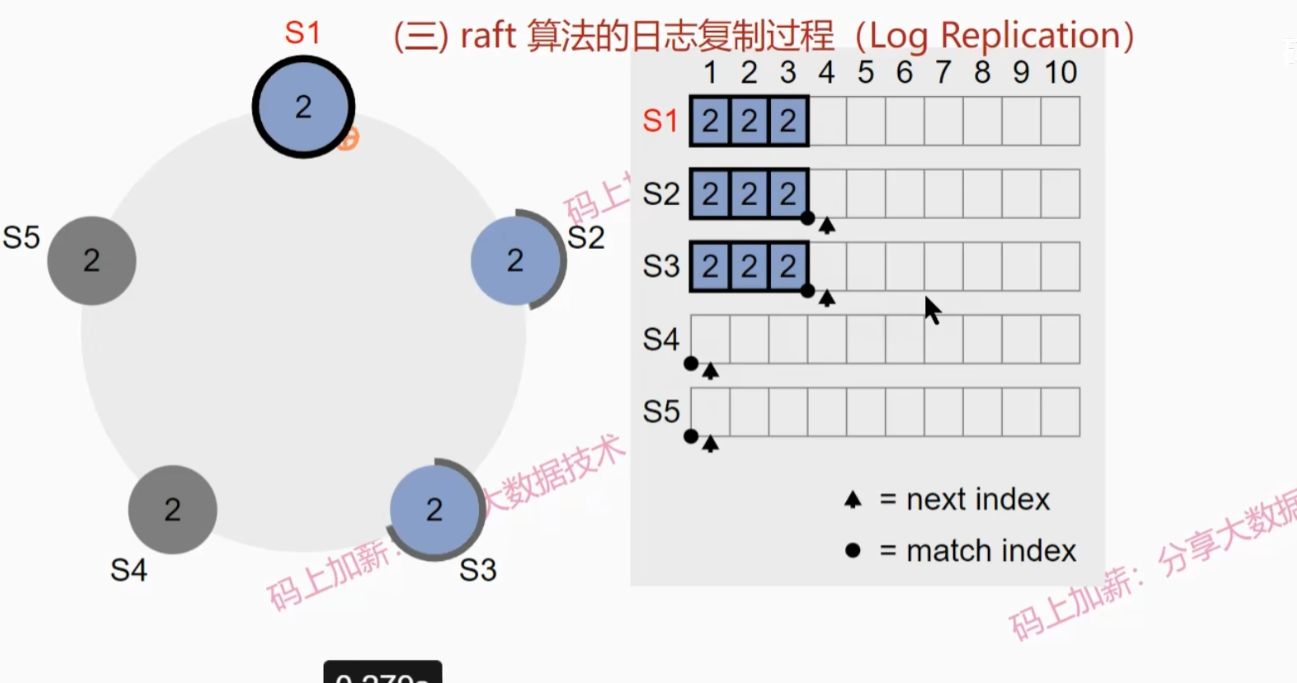
Raft算法的日志复制过程
假设起始情况如下图:
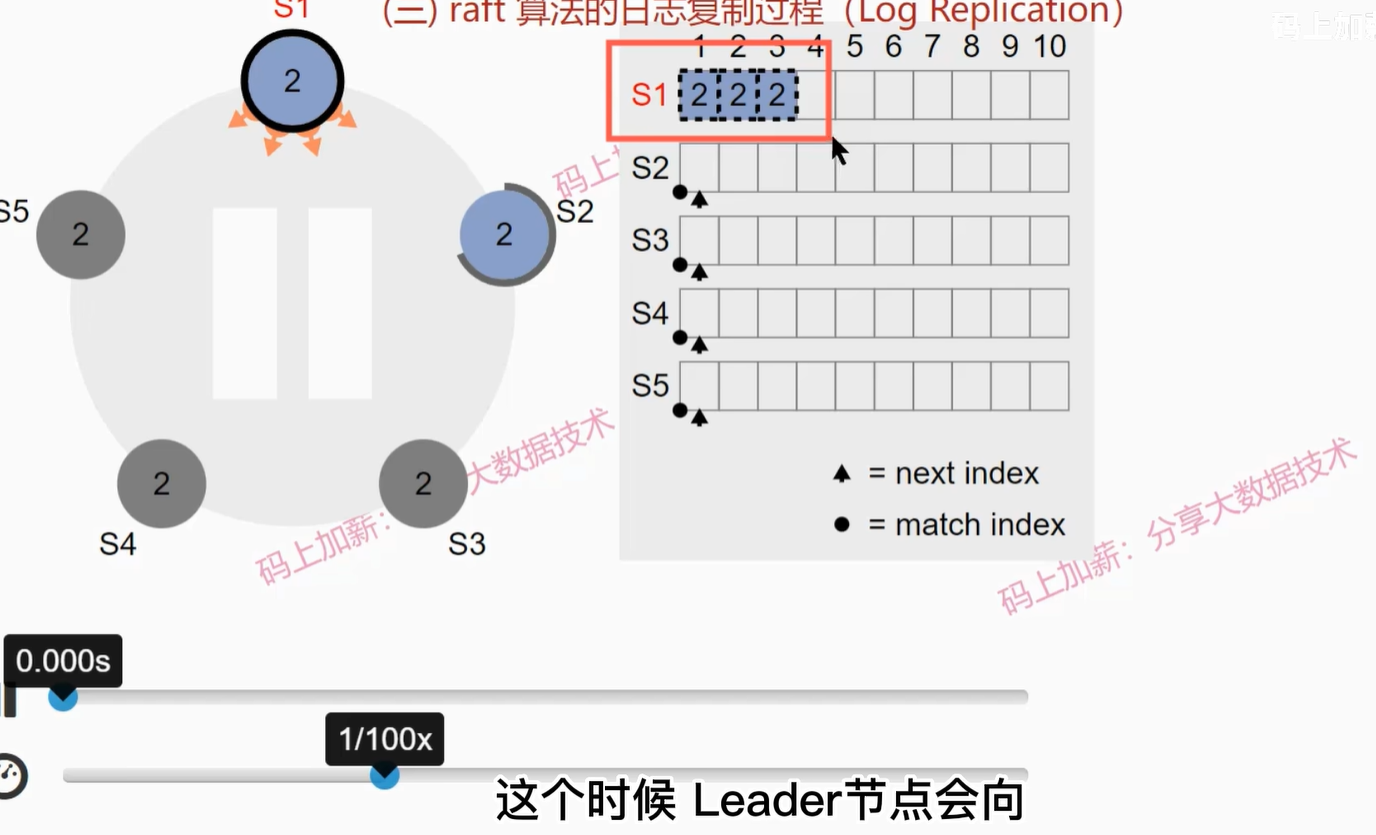
- leader会向其他follower发送日志更新请求
- S2收到日志并写入本地,然后s1继续发送直至s2与s1一致
- 由于只收到一个follower的回复,所以现在还不能提交日志,此时S3恢复
- leader节点会先进行日志探测,寻找S3日志第一个不符位置,然后向S3发送日志同步请求
- S3收到第一条日志写入本地并发送确认,leader接收到确认后由于缓存日志的节点数超过了一半,所以提交了第一个日志
- S3收到第二条复制日志后,会把第一条提交,并发送确认,leader收到确认后提交第二条日志
- leader继续发送第三条复制日志请求,并且会向S2发送日志提交请求(心跳信息),S2会一次性提交2条日志
- leader提交第三条日志,并通知其他两个节点提交第三条日志

Raft-日志分歧
选举约束
如果你去看处理RequestVote的代码和Raft论文的图2,当某个节点为候选人投票时,节点应该将候选人的任期号记录在持久化存储中。(换言之,就算当前server的term记录落后于其他server,也可以通过通信知道下一次选举term值应该是多少,比如S1的term为5,但是S2的term为7,S1下次选举时也知道要从term8开始,而不是term6)
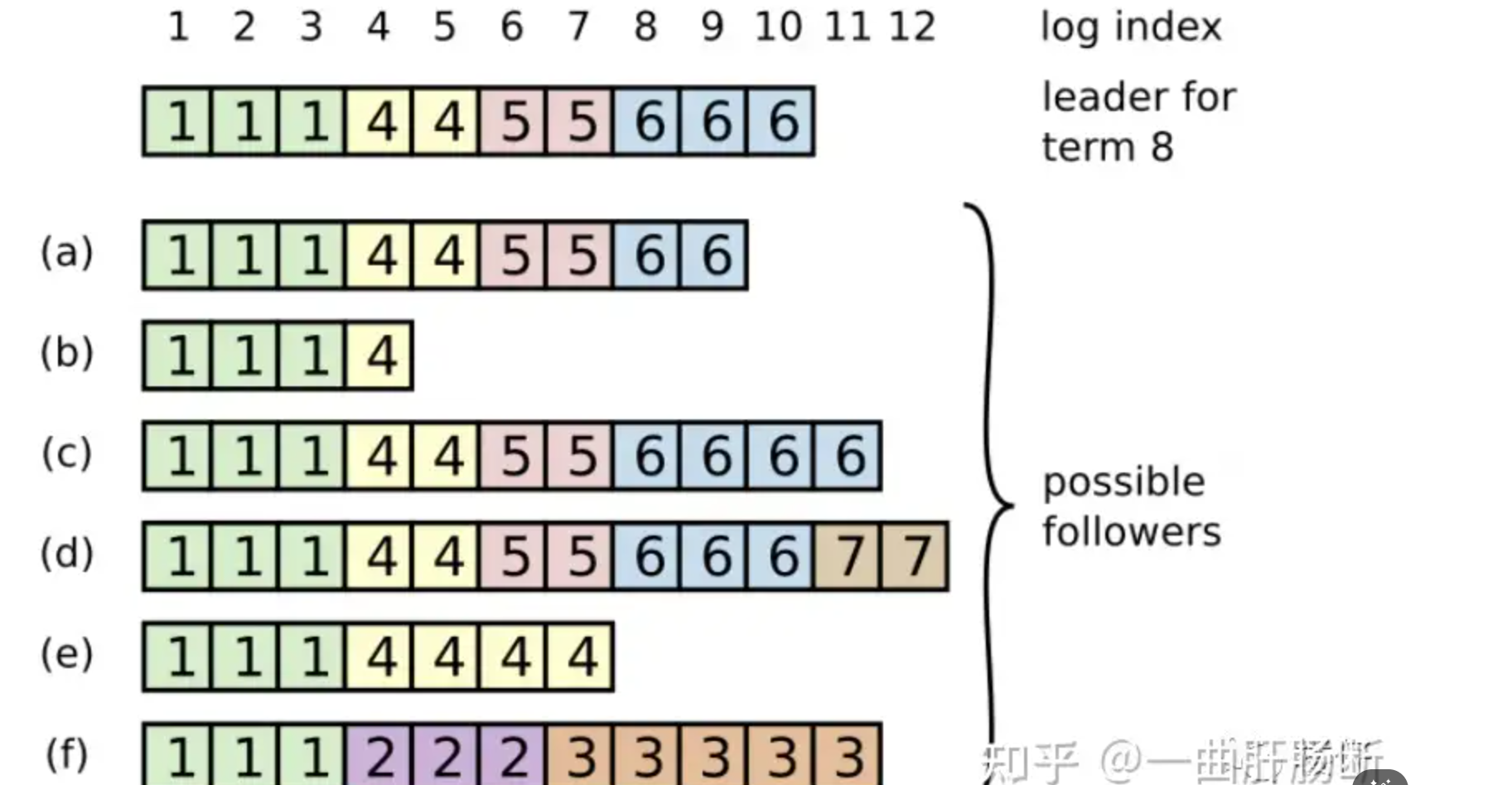
- 根据上述图片我们可以分析出
a 的 term以及index是 6, 9
b 的 term以及index是 4, 4
c 的 term以及index是 6, 11
d 的 term以及index是 7,12
e 的 term以及index是 4, 7
f 的 term以及index是 3,11
我们可以知道可能成为候选人的分别是a, c, d 因为他们可以得到超过半数的票
因为他们发起候选人投票的
Raft选举规则
首先一个候选人发起选举时,调用的RequestVote RPC携带的参数分别是最新的term,该节点最后一条条目的term和index(不管有没有提交),follower接收到这些信息的时候,是拿自己日志中最后一个term和index与收到的term和index进行比较的。不管此日志条目是否提交
有两个规定:
- 候选人的term如果大于投票者的最后一个日志条目的任期就投赞成票
- 如果任期相同则看候选人最后一个日志条目的下标索引是不是更大,是的话就投赞成票
- majority:大多数原则,即至少获取整个系统内大于全部机器数量一半的选票(包括自己,且每人只能投一次票,**宕机的机器也算在系统机器总数内。**如果剩余机器数压根凑不到刚好大于一半的机器数,则没有人能够成功获选)
- at-least-up-to-date:能当选的机器一定是具有最新term的机器(因为 Raft 选举过程中要求的是日志“至少”一样新,而不是严格“必须”拥有最高任期的日志。)
Raft-日志覆写同步(未优化版本)
- 一共有两个指针,分别是:
- nextIndex:所有raft节点都维护nextIndex乐观的变量用于记录下一个需要填充log entry的log index。这里说乐观,因为当leader当选时,leader会初始化nextIndex值为当前log index值+1,表示认为leader自身的log一定是最新的
- matchIndex:leader为所有raft节点(包括leader自己)维护一个悲观的matchIndex用于记录leader和其他follower从0开始往后最长能匹配上的log index的位置+1,表示leader和某个follower在matchIndex之前的所有log entry都是对齐的。这里说悲观,因为leader当选时,leader会初始化matchIndex值为0,表示认为自身log中没有一条记录和其他follower能匹配上。随着leader和其他follower同步消息时,matchIndex会慢慢增加。leader为每个自己的follower维护matchIndex,因为平时根据majority规则,需要保证log已经同步到足够多的followers上。
假设这里有S1~S3三台服务器组成Raft集群,每个Server的log记录如下,(X, Y)表示在log index X有log entry term=Y的log记录:
- S1:(10, 3)
- S2:(10, 3); (11, 3); (12, 5)
- S3:(10, 3); (11, 3); (12, 4)
这里可以看出来S2是term5的leader。
这里S2通过heartbeats流程顺带发起log catch up,即想要和其他followers同步log entry的整体记录情况,按照majority原则,只需要向除了自身外的一台服务器发送消息即可,这里假设向S3发请求。
-
S2向S3,发送heartbeat,携带信息(当前nextIndex指向的term,nextIndex-1的term值,nextIndex-1值),即(空,5,12)
-
S3收到后,检查自己的log发现自己log index12为term4,回复S2一条否定消息no,表明自己还存活,但是不能同意S2要求的append操作,因为S3自己发现自己的log落后了。
-
S2看到S3的否定回应后,认为S3落后于自己,于是将自己的nextIndex从13改成12
-
S2重新发一条请求到S3,这次nextIndex是12,所以携带信息(5, 3, 11)
-
S3接收到后,检查自己log index11的位置为3,发现和S2说的一样,于是按照S2的log记录,在自己log index12的位置将term4改成term5,然后回复S2一条确定消息ok
-
S2收到来自S3的ok后,认为S3这次通信后log和自己对齐是最新的了
-
S2将自己维护的对应S3的matchIndex更新为13,表示log index13之前的log entry,作为leader的S2和作为follower的S3是对齐的
到这里为止,S2能够知道log index12的log entry term5至少在2个server上得到复制(S2和S3),已经满足了majority原则了,所以S2能将消息传递到上层应用了。不幸的是,这不完全是对的。下面会讨论为什么。
这里未优化的版本有个很大的问题,那就是如果Raft集群中出现log落后很多的server,leader需要进行很多次请求才能将其log与自己对齐。
Raft-日志擦除
也就是说,某个leader选举成功之后,不会直接提交前任leader时期的日志,而是通过提交当前任期的日志的时候“顺手”把之前的日志也提交了,具体怎么实现了,在log matching部分有详细介绍。那么问题来了,如果leader被选举后没有收到客户端的请求呢,论文中有提到,在任期开始的时候发立即尝试复制、提交一条空的log
Raft-日志快速覆写同步
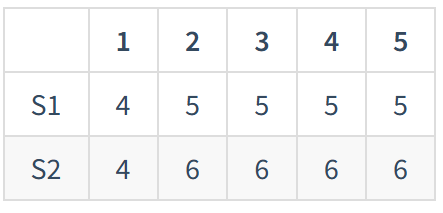
如果通过前面"7.2 Log catch up(unoptimized)"流程,可知道假设S2要向S1同步历史log的记录,那么需要从log index5(nextIndex=6)开始请求,一直请求到log index1(nextIndex=2)的位置后,才能找到S2和S1对齐的第一个位置log index1,然后又以1log index为单位,一直同步到nextIndex=6为止。这显然很浪费网络资源。
这里Log catch up quickly在论文中没有很详细的描述,但是大致流程如下:
- S2假设在term7当选leader,于是nextIndex=6,如之前一样,向S1发送heartbeat时携带log同步信息,(空,6,5),对应(当前nextIndex指向的term,nextIndex-1的term,nextIndex-1值)
- S1收到后,对比自己logIndex5位置为term5。此时S1不再是简单返回no,还顺带回复自己的log信息(即请求中logIndex位置的term值,这个term值最早出现的logIndex位置),这里S1回复(5,2),表示S2heartbeat中说的logIndex5位置自己是term5不对齐,并且term5的值在自己log可追溯到logIndex2
- S2收到回应后,可以直接将nextIndex改成2,并且下次heartbeat携带的信息变成([6,6,6,6], 4, 1),表示nextIndex即往后的数据为[6,6,6,6]
- S1收到heartnbeat后,发现logIndex1是term4是对齐的,于是按照S2说的,将logIndex2开始往后的共4个位置替换成[6,6,6,6]。
当然也可以使用更高级的方法,比如二分来优化,上述流程只是一种方法,意思大概就是一次性否定匹配当前不匹配term第一个出现的位置
Raft-持久化
持久化
Log需要被持久化存储的原因是,这是唯一记录了应用程序状态的地方。Raft论文图2并没有要求我们持久化存储应用程序状态。假如我们运行了一个数据库或者为VMware FT运行了一个Test-and-Set服务,根据Raft论文图2,实际的数据库或者实际的test-set值,并不会被持久化存储,只有Raft的Log被存储了。所以当服务器重启时,唯一能用来重建应用程序状态的信息就是存储在Log中的一系列操作,所以Log必须要被持久化存储。那currentTerm呢?为什么currentTerm需要被持久化存储?是的,currentTerm和votedFor都是用来确保每个任期只有最多一个Leader。在一个故障的场景中,如果一个服务器收到了一个RequestVote请求,并且为服务器1投票了,之后它故障。如果它没有存储它为哪个服务器投过票,当它故障重启之后,收到了来自服务器2的同一个任期的另一个RequestVote请求,那么它还是会投票给服务器2,因为它发现自己的votedFor是空的,因此它认为自己还没投过票。现在这个服务器,在同一个任期内同时为服务器1和服务器2投了票。因为服务器1和服务器2都会为自己投票,它们都会认为自己有过半选票(3票中的2票),那它们都会成为Leader。现在同一个任期里面有了两个Leader。这就是为什么votedFor必须被持久化存储。
currentTerm的情况要更微妙一些,但是实际上还是为了实现一个任期内最多只有一个Leader,我们之前实际上介绍过这里的内容。如果(重启之后)我们不知道任期号是什么,很难确保一个任期内只有一个Leader。
我们这里主要考虑Reboot重启时发生/需要做的事情。
-
策略1:一个Raft节点崩溃重启后,必须重新加入Raft集群。即对于整个Raft集群来说,重启和新加入Raft节点没有太大区别
- 重新加入(re-join),重新加入Raft集群
- 重放日志(replay the log),需要重新执行本地存储的log(我理解上只有未commit的需要重放,当然如果不能区分哪些commit的话,那就是所有现存log需要重放)
策略2:快速重启(start from your persistence state),从上一次存储的持久化状态(快照)的位置开始工作,后续可以通过log catch up的机制,赶上leader的log状态
人们更偏向于策略2,快速重启。这就需要搞清楚,需要持久化哪些状态。
Raft持久化以下状态state:
- vote for:投票情况,因为需要保证每轮term每个server只能投票一次
- log:崩溃前的log记录,因为我们需要保证(promise)已发生的(commit)不会被回退。否则崩溃重启后,可能发生一些奇怪的事情,比如client先前的请求又重新生效一次,导致某个K/V被覆盖成旧值之类的。
- current term:崩溃前的当前term值。因为选举(election)需要用到,用于投票和拉票流程,并且需要保证单调递增(monotonic increasing)
问题:什么时候,server决定进行持久化的动作呢?
回答:每当上面提到的需要持久化的变量state发生变化时,都应该进行持久化,写入稳定存储(磁盘),即使这可能是很昂贵的操作。你必须保证在回复client或者leader的请求之前,先将需要持久化的数据写入稳定存储,然后再回复。否则如果先回复,但是持久化之前崩溃了,你相当于丢失了一些无法找回的记录。
Raft-服务恢复
类似的,服务重启恢复时有两种策略:
- 日志重放(replay log):理论上将log中的记录全部重放一遍,能得到和之前一致的工作状态。这一般来说是很昂贵的策略,特别是工作数年的服务,从头开始执行一遍log,耗时难以估量。所以一般人们不会考虑策略1。
- 周期性快照(periodic snapshots):假设在i的位置创建了快照,那么可以裁剪log,只保留i往后的log。此时重启后可以通过snapshot快照先快速恢复到某个时刻的状态,然后后续可以再通过log catch up或其他手段,将log同步到最新状态。(一般来说周期性的快照不会落后最新版本太多,所以恢复工作要少得多)
这里可以扩展考虑一些场景,比如Raft集群中加入新的follower时,可以让leader将自己的snapshot传递给follower,帮助follower快速同步到近期的状态,尽管可能还是有些落后最新版本,但是根据后续log catch up等机制可以帮助follower随后快速跟进到最新版本log。
使用快照时,需要注意几点:
- 需要拒绝旧版本的快照:有可能收到的snapshot比当前服务状态还老
- 需要保持快照后的log数据:在加载快照时,如果有新log产生,需要保证加载快照后这些新产生的log能够能到保留
线性一致性
在论文中对整个系统提供的服务的正确性称为线性一致性(Linearizability),线性一致性需要保证满足一下三个条件:
-
整体操作顺序一致(total order of operations)
即使操作实际上并发进行,你仍然可以按照整体顺序对它们进行排序。(即后续可以根据读写操作的返回值,对所有读写操作整理出一个符合逻辑的整体执行顺序) -
实时匹配(match real-time)
顺序和真实时间匹配,如果第一个操作在第二个操作开始前就完成,那么在整体顺序中,第一个操作必须排在第二个操作之前(换言之如果这么排序后,整体的执行结果不符合逻辑,那么就不符合"实时匹配")。 -
读操作总是返回最后一次写操作的结果(read return results of last write)
问题:这里说的线性一致性,是不是就是人们说的强一致性?
回答:是的。一般直觉就是表现上像单机,而技术文献中准确定义称为线性一致性。
问题:人们为什么决定定义这个property?(指,线性一致性这个概念为啥会被定义出来)
回答:比如你希望多机系统对外表现如同单机一样,线性一致性就是非常直观的定义。数据库世界中有类似的术语,叫做可串行化(serializability)。基本上线性一致性和可串行化的唯一区别是,可串行化不需要实时匹配(match real-time)。当然,人们对强一致性有不同定义,而我们这里认为线性一致性就是一种强一致性。
问题:可以稍微详细一点介绍clerk吗?
回答:clerk是一个RPC库,它可以帮助记录请求的RPC服务器列表。比如它认为server1是leader,于是Client发请求时,通过clerk会发送到server1,如果server1宕机了,也许clerk根据维护的server列表,会尝试将Client的请求发送到server2,猜测server2是leader。并且clerk会标记每次请求(get、put等),生成请求id,可以帮助server服务检测重复的请求。
问题:论文12页中提到follower擦除旧log,但是不能回滚状态机,是吗?
回答:正如前面日志擦除所说,Raft可以擦除未提交(uncommitted)的log。
问题:server加载snapshot的时候,怎么保证后续还可以接收新的log
回答:可以在加载snapshot之前,先通过COW写时复制的fork创建子进程,子进程加载snapshot,而父进程继续提供服务,例如获取新的log之类的。因为子进程和父进程共享同样的物理内存,所以后续总有办法使得加载完snapshot的子进程获取父进程这段时间内新增的log。
问题:当生成snapshot且因此压缩/删除旧log后,sever维护的log index是从0开始,还是在原本的位置继续往后?
回答:从原本的位置继续往后,不会回退log index索引。