C++asio网络编程
目录
- 目录
- 网络编程的基本流程
- 同步读写
- 同步读写的客户端与服务端
- asio异步读写操作及注意事项
- asio官方案例存在的隐患
- 使用伪闭包实现连接的安全回收
- 封装服务器发送队列
- 修改读回调
- 处理网络粘包问题
- 字节序处理和发送队列控制
- protobuf配置和使用
- jsoncpp的使用与配置
- asio粘包处理的简单方式
- 服务器逻辑层设计和消息完善
- 单例模式实现逻辑层设计
- 服务器优雅退出
- asio多线程模型IOServicePool
- asio多线程模式IOThreadPool
- boost::asio协程实现并发服务器
- 使用asio实现http服务器
- 使用beast网络库实现http服务器
- beast网络库实现websocket服务器
- gRPC的使用
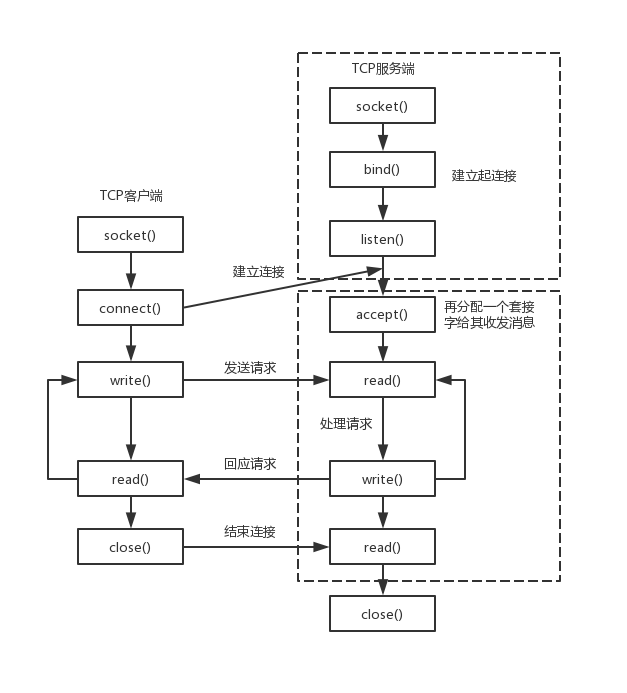
网络编程的基本流程
- 网络编程的基本流程对于服务端是这样的
服务端
1)socket——创建socket对象。
2)bind——绑定本机ip+port。
3)listen——监听来电,若在监听到来电,则建立起连接
4)accept——再创建一个socket对象给其收发消息。原因是现实中服务端都是面对多个客户端,那么为了区分各个客户端,则每个客户端都需再分配一个socket对象进行收发消息。
5)read、write——就是收发消息了。对于客户端是这样的
客户端
1)socket——创建socket对象。
2)connect——根据服务端ip+port,发起连接请求。
3)write、read——建立连接后,就可发收消息了。图示如下
- 了解了解 Reactor模式以及proactor模式
终端节点的创建
- 所谓终端节点就是用来通信的端对端的节点,可以通过ip地址和端口构造,其它节点可以连接这个终端节点做通信。
客户端之终端节点的创建
- 如果我们是客户端,我们可以通过对端的ip和端口构造一个endpoint,用这个endpoint和其通信。
1 |
|
服务端之终端节点的创建
1 | int server_end_point() { |
创建socket
- 创建socket分为4步,创建上下文iocontext,选择协议,生成socket,打开socket。
服务端与客户端之创建socket
1 | int create_tcp_socket() { |
服务端之接收链接请求的socket(对应accept)
1 | int create_acceptor_socket() { |
绑定acceptor
- 对于acceptor类型的socket,服务器要将其绑定到指定的断点,所有连接这个端点的连接都可以被接收到。
1 | int bind_acceptor_socket() { |
可以把端口绑定和acceptor的传建合起来写
1 | // 新版本的写法,默认绑定了8888的端口 |
链接指定的端点
- 作为客户端可以连接服务器指定的端点进行连接
1 | //对应客户端发送链接请求 |
服务器接收来连接
- 当有客户端连接时,服务器需要接收连接
1 | int accept_new_connection() { |
在早期版本的 Boost.Asio 中,在使用 ip::tcp::acceptor 对象之前,通常需要调用 bind 函数将 acceptor 绑定到特定的地址和端口上,并调用 listen 函数开始监听连接请求。
但在较新的版本中,Boost.Asio 已经做了一些改进,使得在创建 ip::tcp::acceptor 对象时可以通过构造函数直接指定绑定地址和端口,并且开始监听连接请求。这样可以简化代码,并且提供了更方便的接口。
创建acceptor的几种方法
当使用 Boost.Asio 创建 TCP 服务器时,通常有以下几种方法来创建 acceptor 对象:
使用端点对象创建 acceptor:
这是最常见的方法。你首先创建一个 TCP 端点对象(boost::asio::ip::tcp::endpoint),指定要监听的特定地址和端口。然后,使用这个端点对象来创建 acceptor 对象。
1 | boost::asio::ip::tcp::endpoint endpoint(boost::asio::ip::address_v4::any(), 8888); |
使用协议对象创建 acceptor:
- 你也可以直接使用 TCP 协议对象(boost::asio::ip::tcp::v4() 或 boost::asio::ip::tcp::v6())来创建 acceptor 对象。在这种情况下,acceptor 将监听服务器上的所有网络接口。
1 | boost::asio::io_context io_context; |
延迟绑定端口:
- 有时你可能希望在创建 acceptor 对象后,稍后再将其绑定到指定的地址和端口上。这样的话,在创建 acceptor 时不需要传递端点对象或协议对象。
1 | boost::asio::io_context io_context; |
- 总的来说,创建 acceptor 对象的方法取决于你的需求。如果你想监听特定的地址和端口,则使用端点对象或协议对象;如果你希望在稍后再绑定端口,则延迟绑定端口。
关于buffer
- 任何网络库都有提供buffer的数据结构,所谓buffer就是接收和发送数据时缓存数据的结构。
- boost::asio提供了asio::mutable_buffer 和 asio::const_buffer这两个结构,他们是一段连续的空间,首字节存储了后续数据的长度。
- asio::mutable_buffer用于写服务,asio::const_buffer用于读服务。但是这两个结构都没有被asio的api直接使用。
- 对于api的buffer参数,asio提出了MutableBufferSequence和ConstBufferSequence概念,他们是由多个asio::mutable_buffer和asio::const_buffer组成的。也就是说boost::asio为了节省空间,将一部分连续的空间组合起来,作为参数交给api使用。
- 我们可以理解为MutableBufferSequence的数据结构为std::vector
结构如下
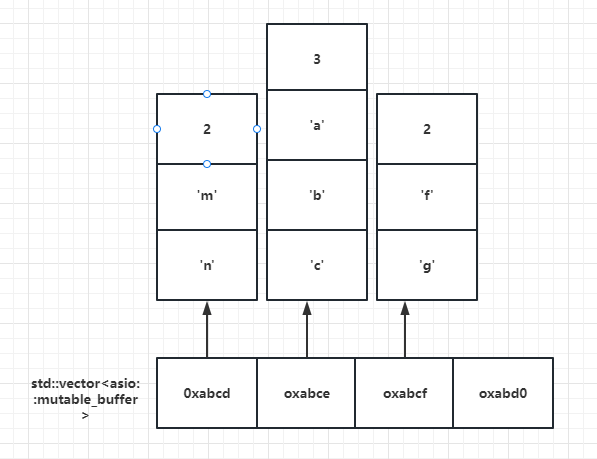
- 每个vector存储的都是mutable_buffer的地址,每个mutable_buffer的第一个字节表示数据的长度,后面跟着数据内容。
- 这么复杂的结构交给用户使用并不合适,所以asio提出了buffer()函数,该函数接收多种形式的字节流,该函数返回asio::mutable_buffers_1 o或者asio::const_buffers_1结构的对象。
- 如果传递给buffer()的参数是一个只读类型,则函数返回asio::const_buffers_1 类型对象。
- 如果传递给buffer()的参数是一个可写类型,则返回asio::mutable_buffers_1 类型对象。
- asio::const_buffers_1和asio::mutable_buffers_1是asio::mutable_buffer和asio::const_buffer的适配器,提供了符合MutableBufferSequence和ConstBufferSequence概念的接口,所以他们可以作为boost::asio的api函数的参数使用。
- 简单概括一下,我们可以用buffer()函数生成我们要用的缓存存储数据。
比如boost的发送接口send要求的参数为ConstBufferSequence类型
1 | template<typename ConstBufferSequence> |
- 我们需要手动转换
1 | // 模拟构造const_buffer的结构,这样写非常的麻烦 |
字符串的buffer
- 最终buffers_sequence就是可以传递给发送接口send的类型。但是这太复杂了,可以直接用buffer函数转化为send需要的参数类型
1 | // 他会自动模拟上述操作 |
- output_buf可以直接传递给该send接口。我们也可以将数组转化为send接受的类型
数组的buffer
1 | void use_buffer_array() { |
- 其中可以不强制转换为void*
流式的buffer
- 对于流式操作,我们可以用streambuf,将输入输出流和streambuf绑定,可以实现流式输入和输出。
1 | void use_stream_buffer() { |
容器的buffer
1 | std::vector<char> data = { /* 初始化数据 */ }; |
指向缓冲区的指针的buffer
1 | char data[1024]; |
同步读写
同步写 write_some
- boost::asio提供了几种同步写的api,write_some可以每次向指定的空间写入固定的字节数,如果写缓冲区满了,就只写一部分,返回写入的字节数。
1 | void write_to_socket(boost::asio::ip::tcp::socket& sock) { |
1 | void send_data_by_write_some(){ |
同步写 send
- write_some使用起来比较麻烦,需要多次调用,asio提供了send函数。send函数会一次性将buffer中的内容发送给对端,如果有部分字节因为发送缓冲区满无法发送,则阻塞等待,直到发送缓冲区可用,则继续发送完成。
1 | void send_data_by_send() { |
同步写 write
- 类似send方法,asio还提供了一个write函数,可以一次性将所有数据发送给对端,如果发送缓冲区满了则阻塞,直到发送缓冲区可用,将数据发送完成。
1 | void send_data_by_write() { |
同步读 read_some
- 同步读和同步写类似,提供了读取指定字节数的接口read_some
1 | std::string read_from_socket(boost::asio::ip::tcp::socket& sock) { |
1 | void read_data_by_read_some() { |
同步读 receive
- 可以一次性同步接收对方发送的数据
1 | int read_data_by_receive() { |
同步读 read
- 可以一次性同步读取对方发送的数据
1 | using namespace boost; |
读取直到指定字符
- 我们可以一直读取,直到读取指定字符结束
1 | std::string read_data_by_until(asio::ip::tcp::socket& sock) { |
同步读写的客户端与服务端
- 前面我们介绍了boost::asio同步读写的api函数,现在将前面的api串联起来,做一个能跑起来的客户端和服务器。
- 客户端和服务器采用阻塞的同步读写方式完成通信
客户端的设计
- 客户端设计基本思路是根据服务器对端的ip和端口创建一个endpoint,然后创建socket连接这个endpoint,之后就可以用同步读写的方式发送和接收数据了。
1 |
|
服务端设计
session函数
- 创建session函数,该函数为服务器处理客户端请求,每当我们获取客户端连接后就调用该函数。在session函数里里进行echo方式的读写,所谓echo就是应答式的处理
1 | void session(socket_ptr sock) { |
server函数
- server函数根据服务器ip和端口创建服务器acceptor用来接收数据,用socket接收新的连接,然后为这个socket创建session。
1 | void server(boost::asio::io_context& io_context, unsigned short port) { |
- 创建线程调用session函数可以分配独立的线程用于socket的读写,保证acceptor不会因为socket的读写而阻塞。
完整服务端代码
1 |
|
同步读写的优劣
- 同步读写的缺陷在于读写是阻塞的,如果客户端对端不发送数据服务器的read操作是阻塞的,这将导致服务器处于阻塞等待状态。
- 可以通过开辟新的线程为新生成的连接处理读写,但是一个进程开辟的线程是有限的,约为2048个线程,在Linux环境可以通过unlimit增加一个进程开辟的线程数,但是线程过多也会导致切换消耗的时间片较多。
- 该服务器和客户端为应答式,实际场景为全双工通信模式,发送和接收要独立分开。
- 该服务器和客户端未考虑粘包处理。
- 综上所述,是我们这个服务器和客户端存在的问题,为解决上述问题,我们在接下里的文章里做不断完善和改进,主要以异步读写改进上述方案。
当然同步读写的方式也有其优点,比如客户端连接数不多,而且服务器并发性不高的场景,可以使用同步读写的方式。使用同步读写能简化编码难度。
asio异步读写操作及注意事项
- 我们定义一个session类,这个session类表示服务器处理客户端连接的管理类
1 |
|
1 |
|
异步写操作
- 在写操作前,我们先封装一个Node结构,用来管理要发送和接收的数据,该结构包含数据域首地址,数据的总长度,以及已经处理的长度(已读的长度或者已写的长度)
1 | class MsgNode { |
写了两个构造函数,两个参数的负责构造写节点,一个参数的负责构造读节点。
接下来为Session添加异步写操作和负责发送写数据的节点
1 | class Session |
- WriteToSocketErr函数为我们封装的写操作,WriteCallBackErr为异步写操作回调的函数,为什么会有三个参数呢,
- 我们可以看一下asio源码
1 | BOOST_ASIO_COMPLETION_TOKEN_FOR(void (boost::system::error_code, |
- sync_write_some是异步写的函数,这个异步写函数有两个参数,第一个参数为ConstBufferSequence常引用类型的buffers,
- 第二个参数为WriteToken类型,而WriteToken在上面定义了,是一个函数对象类型,返回值为void,参数为error_code和size_t,
- 所以我们为了调用async_write_some函数也要传入一个符合WriteToken定义的函数,就是我们声明的WriteCallBackErr函数,
前两个参数为WriteToken规定的参数,第三个参数为MsgNode的智能指针,这样通过智能指针保证我们发送的Node生命周期延长。
我们看一下WriteToSocketErr函数的具体实现
1 | void Session::WriteToSocketErr(const std::string buf) |
因为WriteCallBackErr函数为三个参数且为成员函数,而async_write_some需要的回调函数为两个参数,所以我们通过bind将三个参数转换为两个参数的普通函数。
我们看看回调函数的实现
1 | void Session::WriteCallBackErr(const boost::system::error_code& ec, std::size_t bytes_transferred, std::shared_ptr<MsgNode> msg_node) |
- 在WriteCallBackErr函数里判断如果已经发送的字节数没有达到要发送的总字节数,那么就更新节点已经发送的长度,然后计算剩余要发送的长度,如果有数据未发送完,再次调用async_write_some函数异步发送。
- 但是这个函数并不能投入实际应用,因为async_write_some回调函数返回已发送的字节数可能并不是全部长度。比如TCP发送缓存区总大小为8字节,但是有3字节未发送(上一次未发送完),这样剩余空间为5字节
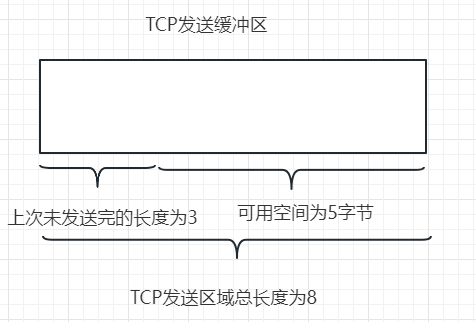
- 此时我们调用async_write_some发送hello world!实际发送的长度就是为5,也就是只发送了hello,剩余world!通过我们的回调继续发送。
而实际开发的场景用户是不清楚底层tcp的多路复用调用情况的,用户想发送数据的时候就调用WriteToSocketErr,或者循环调用WriteToSocketErr,很可能在一次没发送完数据还未调用回调函数时再次调用WriteToSocketErr,因为boost::asio封装的是epoll和iocp等多路复用模型,当写事件就绪后就发数据,发送的数据按照async_write_some调用的顺序发送,所以回调函数内调用的async_write_some可能并没有被及时调用。
比如如下代码:
1 | //用户发送数据 |
- 那么很可能第一次只发送了Hello,后面的数据没发完,第二次发送了Hello World!之后又发送了World!
所以对端收到的数据很可能是”HelloHello World! World!”
那怎么解决这个问题呢,我们可以通过队列保证应用层的发送顺序。我们在Session中定义一个发送队列,然后重新定义正确的异步发送函数和回调处理
1 | class Session |
- 定义了bool变量_send_pending,该变量为true表示一个节点还未发送完。
_send_queue用来缓存要发送的消息节点,是一个队列。
我们实现异步发送功能
1 | void Session::WriteCallBack(const boost::system::error_code& ec, std::size_t bytes_transferred) |
- async_write_some函数不能保证每次回调函数触发时发送的长度为要总长度,这样我们每次都要在回调函数判断发送数据是否完成,asio提供了一个更简单的发送函数async_send,这个函数在发送的长度未达到我们要求的长度时就不会触发回调,所以触发回调函数时要么时发送出错了要么是发送完成了,其内部的实现原理就是帮我们不断的调用async_write_some直到完成发送,所以async_send不能和async_write_some混合使用,我们基于async_send封装另外一个发送函数
1 | //这个回调函数被调用并且没有异常肯定是发完了一个数据 |
异步读操作
接下来介绍异步读操作,异步读操作和异步的写操作类似同样又async_read_some和async_receive函数,前者触发的回调函数获取的读数据的长度可能会小于要求读取的总长度,后者触发的回调函数读取的数据长度等于读取的总长度。
先基于async_read_some封装一个读取的函数ReadFromSocket,同样在Session类的声明中添加一些变量
1 | void Session::ReadFromSocket() { |
- 我们基于async_receive再封装一个接收数据的函数
1 | void Session::ReadAllFromSocket() { |
总结 完整代码
Session.h头文件
1 |
|
Session.cpp
1 |
|
- 发送的时候推荐使用 asyc_send 而接受的时候 推荐使用 asyc_rend_some 函数
asio官方案例存在的隐患
Session类
- Session类主要是处理客户端消息收发的会话类,为了简单起见,我们不考虑粘包问题,也不考虑支持手动调用发送的接口,只以应答的方式发送和接收固定长度(1024字节长度)的数据。
1 |
|
- _data用来接收客户端传递的数据
- socket为单独处理客户端读写的socket。
- handle_read和handle_write分别为读回调函数和写回调函数。
- 接下来我们实现Session类
1 |
|
- 在Start方法中我们调用异步读操作,监听对端发送的消息。当对端发送数据后,触发handle_read函数
- handle_read函数内将收到的数据发送给对端,当发送完成后触发handle_write回调函数。
- handle_write函数内又一次监听了读事件,如果对端有数据发送过来则触发handle_read,我们再将收到的数据发回去。从而达到应答式服务的效果。
Server类
- Server类为服务器接收连接的管理类
1 | class Server { |
Server实现
1 | Server::Server(boost::asio::io_context& ioc, unsigned short port) : _ioc(ioc), _acceptor(ioc, boost::asio::ip::tcp::endpoint(boost::asio::ip::tcp::v4(), port)) { |
隐患
- 该demo示例为仿照asio官网编写的,其中存在隐患,就是当服务器即将发送数据前(调用async_write前),此刻客户端中断,服务器此时调用async_write会触发发送回调函数,判断ec为非0进而执行delete this逻辑回收session。但要注意的是客户端关闭后,在tcp层面会触发读就绪事件,服务器会触发读事件回调函数。在读事件回调函数中判断错误码ec为非0,进而再次执行delete操作,从而造成二次析构,这是极度危险的。
总结
- 本文介绍了异步的应答服务器设计,但是这种服务器并不会在实际生产中使用,主要有两个原因:
- 因为该服务器的发送和接收以应答的方式交互,而并不能做到应用层想随意发送的目的,也就是未做到完全的收发分离(全双工逻辑)。
- 该服务器未处理粘包,序列化,以及逻辑和收发线程解耦等问题。
- 该服务器存在二次析构的风险。
- 对于官方案例,他考虑到了这个二次析构问题,所以它只会在读成功后进行写,这就保证了同一时期只有一个读取或者写(单工),但是这依然是一个隐患。
完整代码
头文件
1 |
|
实现
1 |
|
使用伪闭包实现连接的安全回收
- 之前的异步服务器为echo模式,但其存在安全隐患,就是在极端情况下客户端关闭导致触发写和读回调函数,二者都进入错误处理逻辑,进而造成二次析构的问题。
- 下面我们介绍通过C11智能指针构造成一个伪闭包的状态延长session的生命周期。
智能指针管理Session
- 我们可以通过智能指针的方式管理Session类,将acceptor接收的链接保存在Session类型的智能指针里。由于智能指针会在引用计数为0时自动析构,所以为了防止其被自动回收,也方便Server管理Session,因为我们后期会做一些重连踢人等业务逻辑,我们在Server类中添加成员变量,该变量为一个map类型,key为Session的uid,value为该Session的智能指针。
1 | class CServer |
通过Server中的_sessions这个map管理链接,可以增加Session智能指针的引用计数,只有当Session从这个map中移除后,Session才会被释放。
所以在接收连接的逻辑里将Session放入map
1 | void CServer::StartAccept() { |
- StartAccept函数中虽然new_session是一个局部变量,但是我们通过bind操作,将new_session作为数值传递给bind函数,而bind函数返回的函数对象内部引用了该new_session所以引用计数增加1,这样保证了new_session不会被释放。
在HandleAccept函数里调用session的start函数监听对端收发数据,并将session放入map中,保证session不被自动释放。
此外,需要封装一个释放函数,将session从map中移除,当其引用计数为0则自动释放
1 | void CServer::ClearSession(std::string& uuid) { |
Session的uuid
- 关于session的uuid可以通过boost提供的生成唯一id的函数获得,当然你也可以自己实现雪花算法。
1 | CSession(boost::asio::io_context& ioc, CServer* server) :sock(ioc),_server(server) { |
- 另外我们修改Session中读写回调函数关于错误的处理,当读写出错的时候清除连接
1 | void CSession::Start() { |
隐患1
- 正常情况下上述服务器运行不会出现问题,但是当我们像上次一样模拟,在服务器要发送数据前打个断点,此时关闭客户端,在服务器就会先触发写回调函数的错误处理,再触发读回调函数的错误处理,这样session就会两次从map中移除,因为map中key唯一,所以第二次map判断没有session的key就不做移除操作了。
- 但是这么做还是会有崩溃问题,因为第一次在session写回调函数中移除session,session的引用计数就为0了,调用了session的析构函数,这样在触发session读回调函数时此时session的内存已经被回收了自然会出现崩溃的问题。解决这个问题可以利用智能指针引用计数和bind的特性,实现一个伪闭包的机制延长session的生命周期。
如何实现伪闭包
思路:
- 利用智能指针被复制或使用引用计数加一的原理保证内存不被回收
- bind操作可以将值绑定在一个函数对象上生成新的函数对象,如果将智能指针作为参数绑定给函数对象,那么智能指针就以值的方式被新函数对象使用,那么智能指针的生命周期将和新生成的函数对象一致,从而达到延长生命的效果。
- 以HandleWrite举例,在bind时传递_self_shared指针增加其引用计数,这样_self_shared的生命周期就和async_write的第二个参数(也就是asio要求的回调函数对象)生命周期一致了。
- 除此之外,我们也要在第一次绑定读写回调函数的时候传入智能指针的值,但是要注意传入的方式,不能用两个智能指针管理同一块内存,如下用法是错误的。
- shared_ptr
(this)生成的新智能指针和this之前绑定的智能指针并不共享引用计数,所以要通过shared_from_this()函数返回智能指针,该智能指针和其他管理这块内存的智能指针共享引用计数。 - shared_from_this()函数并不是session的成员函数,要使用这个函数需要继承std::enable_shared_from_this
完整的代码
实现1
1 |
|
头文件1
1 |
|
封装服务器发送队列
- 封装发送队列来保证发送数据的有序性
数据节点设计
1 |
|
- _cur_len表示数据当前已处理的长度(已经发送的数据或者已经接收的数据长度),因为一个数据包存在未发送完或者未接收完的情况。
- _max_len表示数据的总长度。
- _data表示数据域,已接收或者已发送的数据都放在此空间内。
封装发送接口
首先在CSession类里新增一个队列存储要发送的数据,因为我们不能保证每次调用发送接口的时候上一次数据已经发送完,就要把要发送的数据放入队列中,通过回调函数不断地发送。而且我们不能保证发送的接口和回调函数的接口在一个线程,所以要增加一个锁保证发送队列安全性。
我们新增一个发送接口Send
1 | // 发送接口 |
- 实现发送接口
1 | void CSession::Send(char* msg, int max_length) { |
发送接口里判断发送队列是否为空,如果不为空说明有数据未发送完,需要将数据放入队列,然后返回。如果发送队列为空,则说明当前没有未发送完的数据,将要发送的数据放入队列并调用async_write函数发送数据。
回调函数的实现
1 | void CSession::HandleWrite(const boost::system::error_code& error, std::shared_ptr<CSession> _self_shared) { |
- 判断发送队列是否为空,为空则发送完,否则不断取出队列数据调用async_write发送,直到队列为空。
修改读回调
- 因为我们要一直监听对端发送的数据,所以要在每次收到数据后继续绑定监听事件
1 | void CSession::HandleRead(const boost::system::error_code& error, |
该节总结
- 虽然实现了全双工,但是未处理粘包问题
封装后完整代码
msgNode
1 |
|
CSession
1 |
|
1 |
|
CServer
1 |
|
1 |
|
处理网络粘包问题
什么是粘包
- 粘包问题是服务器收发数据常遇到的一个现象,当客户端发送多个数据包给服务器时,服务器底层的tcp接收缓冲区收到的数据为粘连在一起的,如下图所示:
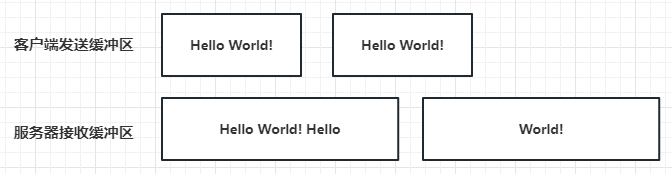
- 当客户端发送两个Hello World!给服务器,服务器TCP接收缓冲区接收了两次,一次是Hello World!Hello, 第二次是World!。
粘包原因
- 因为TCP底层通信是面向字节流的,TCP只保证发送数据的准确性和顺序性,字节流以字节为单位,客户端每次发送N个字节给服务端,N取决于当前客户端的发送缓冲区是否有数据,比如发送缓冲区总大小为10个字节,当前有5个字节数据(上次要发送的数据比如’loveu’)未发送完,那么此时只有5个字节空闲空间,我们调用发送接口发送hello world!其实就是只能发送Hello给服务器,那么服务器一次性读取到的数据就很可能是loveuhello。而剩余的world!只能留给下一次发送,下一次服务器接收到的就是world!如下图:
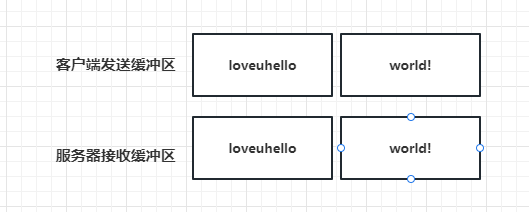
- 这是最好理解的粘包问题的产生原因。还有一些其他的原因比如
- 客户端的发送频率远高于服务器的接收频率,就会导致数据在服务器的tcp接收缓冲区滞留形成粘连,比如客户端1s内连续发送了两个hello world!,服务器过了2s才接收数据,那一次性读出两个hello world!。
- tcp底层的安全和效率机制不允许字节数特别少的小包发送频率过高,tcp会在底层累计数据长度到一定大小才一起发送,比如连续发送1字节的数据要累计到多个字节才发送,可以了解下tcp底层的Nagle算法。
- 再就是我们提到的最简单的情况,发送端缓冲区有上次未发送完的数据或者接收端的缓冲区里有未取出的数据导致数据粘连。
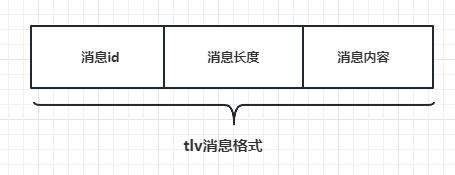
处理粘包
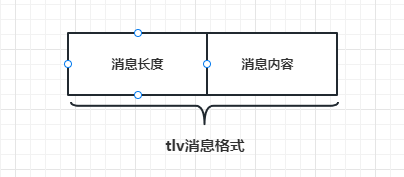
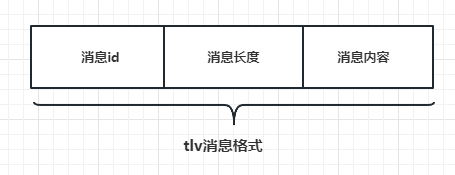
- 处理粘包的方式主要采用应用层定义收发包格式的方式,这个过程俗称切包处理,常用的协议被称为tlv协议(消息id+消息长度+消息内容),如下图:
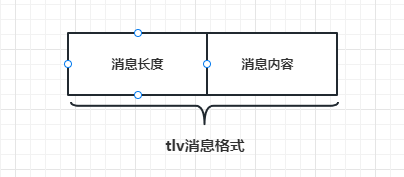
- 为保证大家容易理解,我们先简化发送的格式,格式变为消息长度+消息内容的方式,之后再完善为tlv格式。
- 简化后的结构如下图:
完善消息节点
1 |
|
- 两个参数的构造函数做了完善,之前的构造函数通过消息首地址和长度构造节点数据,现在需要在构造节点的同时把长度信息也写入节点,该构造函数主要用来发送数据时构造发送信息的节点。
- 一个参数的构造函数为较上次新增的,主要根据消息的长度构造消息节点,该构造函数主要是接收对端数据时构造接收节点调用的。
- 新增一个Clear函数清除消息节点的数据,主要是避免多次构造节点造成开销。
- 数据这么传输
CSession类完善
- 为能够对收到的数据切包处理,需要定义一个消息接收节点,一个bool类型的变量表示头部是否解析完成,以及将处理好的头部先缓存起来的结构。
1 | //收到的消息结构 |
- _recv_msg_node用来存储接受的消息体信息
- _recv_head_node用来存储接收的头部信息
_b_head_parse表示是否处理完头部信息
同时我们新增一个HEAD_LENGTH变量表示数据包头部的大小,修改原消息最大长度为1024*2
1 | constexpr int MAX_LENGTH = 1024 * 2; |
- 修改完后的头文件
1 |
|
完善接收逻辑
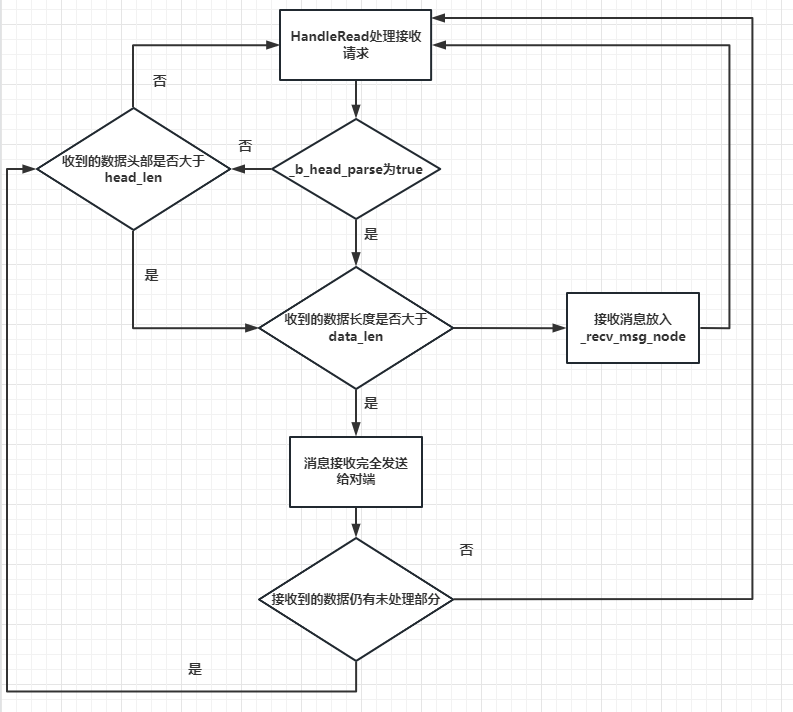
- 需要修改HandleRead函数
1 | //第二个参数为你接收到的需要读的字节数,第三个参数增加引用计数,防止未处理为就被析构以及二次析构问题 |
- copy_len记录的是已经处理过数据的长度,因为存在一次接收多个包的情况,所以copy_len用来做已经处理的数据长度的。
- 首先判断_b_head_parse是否为false,如果为false则说明头部未处理,先判断接收的数据是否小于头部, 如果小于头部大小则将接收到的数据放入_recv_head_node节点保存,然后继续调用读取函数监听对端发送数据。否则进入步骤3.
- 如果收到的数据比头部多,可能是多个逻辑包,所以要做切包处理。根据之前保留在_recv_head_node的长度,计算出剩余未取出的头部长度,然后取出剩余的头部长度保存在_recv_head_node节点,然后通过memcpy方式从节点拷贝出数据写入short类型的data_len里,进而获取消息的长度。接下来继续处理包体,也就是消息体,判断接收到的数据未处理部分的长度和总共要接收的数据长度大小,如果小于总共要接受的长度,说明消息体没接收完,则将未处理部分先写入_recv_msg_node里,并且继续监听读事件。否则说明消息体接收完全,进入步骤4
- 将消息体数据接收到_recv_msg_node中,接受完全后返回给对端。当然存在多个逻辑包粘连,此时要判断bytes_transferred是否小于等于0,如果是说明只有一个逻辑包,我们处理完了,继续监听读事件,就直接返回即可。否则说明有多个数据包粘连,就继续执行上述操作。
- 因为存在_b_head_parse为true,也就是包头接收并处理完的情况,但是包体未接受完,再次触发HandleRead,此时要继续处理上次未接受完的消息体,大体逻辑和3,4一样。
- 以上就是处理粘包的过程,我们绘制流程图更明了一些
服务端完整代码
CSession头文件
1 |
|
CSession 实现
1 |
|
CServer头文件
1 |
|
CServer实现
1 |
|
MsgNode
1 |
|
客户端修改
- 客户端的发送也要遵循先发送数据2个字节的数据长度,再发送数据消息的结构。
接收时也是先接收两个字节数据获取数据长度,再根据长度接收消息。
1 |
|
粘包测试
为了测试粘包,需要制造粘包产生的现象,可以让客户端发送的频率高一些,服务器接收的频率低一些,这样造成前后端收发数据不一致导致多个数据包在服务器tcp缓冲区滞留产生粘包现象。
测试粘包之前,在服务器的CSession类里添加打印二进制数据的函数,便于查看缓冲区的数据
1 | //头文件#include <iomanip> |
- 然后将这个函数放到HandleRead里,每次收到数据就调用这个函数打印接收到的最原始的数据,然后睡眠2秒再进行收发操作,用来延迟接收对端数据制造粘包,之后的逻辑不变
1 | void CSession::HandleRead(const boost::system::error_code& error, size_t bytes_transferred, std::shared_ptr<CSession> shared_self){ |
- 修改客户端逻辑实现手收发分离
1 |
|
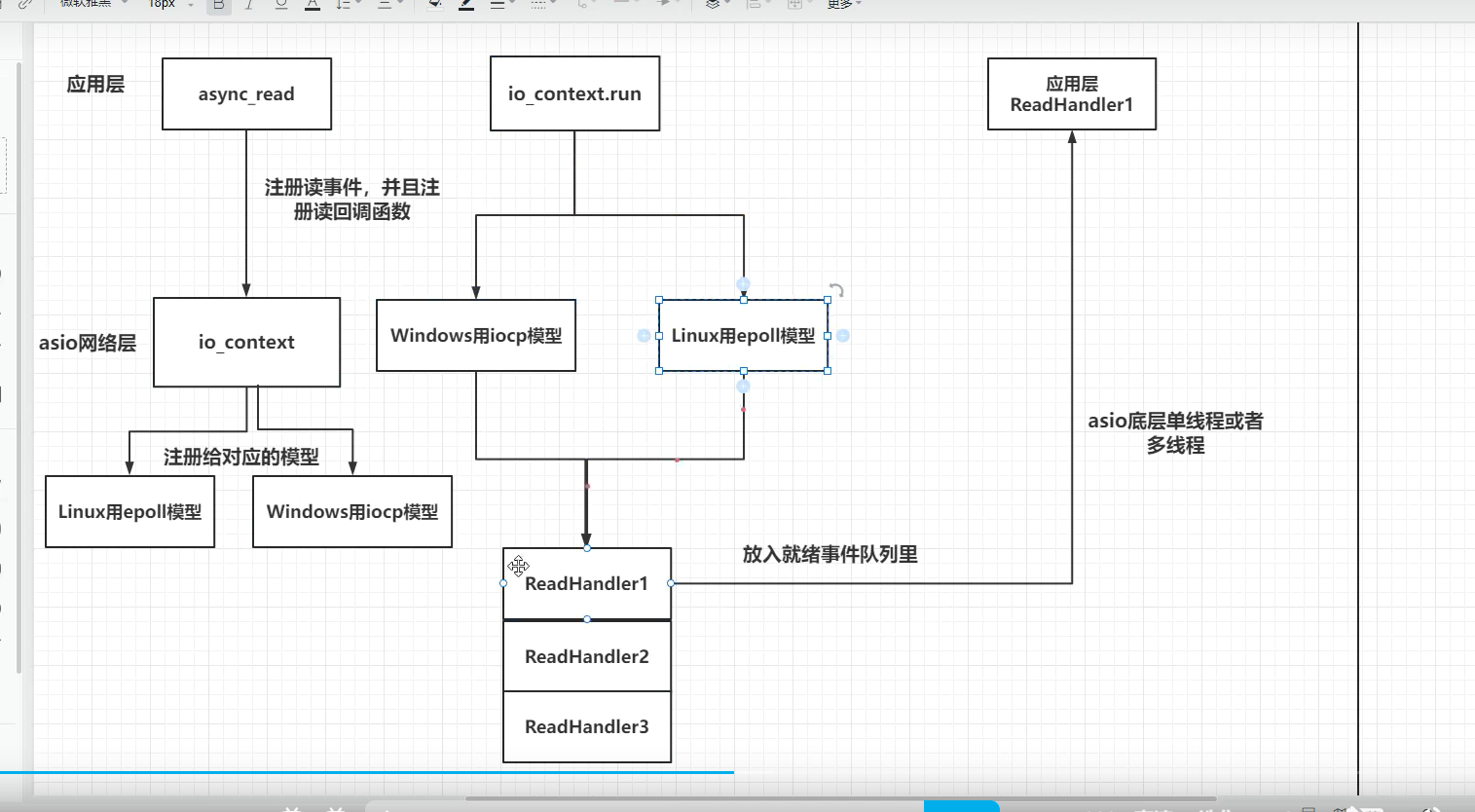
目前服务端通信流程图
io_context
- 里面维护了一个队列,会把注册的回调函数以及读写函数写入队列中
字节序处理和发送队列控制
字节序问题
在计算机网络中,由于不同的计算机使用的 CPU 架构和字节顺序可能不同,因此在传输数据时需要对数据的字节序进行统一,以保证数据能够正常传输和解析。这就是网络字节序的作用。
具体来说,计算机内部存储数据的方式有两种:大端序(Big-Endian)和小端序(Little-Endian)。在大端序中,高位字节存储在低地址处,而低位字节存储在高地址处;在小端序中,高位字节存储在高地址处,而低位字节存储在低地址处。
在网络通信过程中,通常使用的是大端序。这是因为早期的网络硬件大多采用了 Motorola 处理器,而 Motorola 处理器使用的是大端序。此外,大多数网络协议规定了网络字节序必须为大端序。
因此,在进行网络编程时,需要将主机字节序转换为网络字节序,也就是将数据从本地字节序转换为大端序。可以使用诸如 htonl、htons、ntohl 和 ntohs 等函数来实现字节序转换操作。
综上所述,网络字节序的主要作用是统一不同计算机间的数据表示方式,以保证数据在网络中的正确传输和解析。
如何区分本机字节序
- 如何区分本机字节序,可以通过判断低地址存储的数据是否为低字节数据,如果是则为小端,否则为大端,下面写一段代码讲述这个逻辑
1 |
|
在上述代码中,使用了一个 is_big_endian() 函数来判断当前系统的字节序是否为大端序。该函数通过创建一个整型变量 num,并将其最低位设置为 1,然后通过指针强制转换成字符指针,判断第一个字节是否为 1 来判断当前系统的字节序。
在 main 函数中,定义了一个整型变量 num,并将其初始化为 0x12345678。接着,使用 char* 类型的指针 p 来指向 num 的地址。然后,通过判断当前系统的字节序来输出 num 的字节序。
如果当前系统为大端序,则按照原始顺序输出各个字节;如果当前系统为小端序,则需要逆序输出各个字节。
大端模式

- 小端模式

服务器使用网络字节序
- 为保证字节序一致性,网络传输使用网络字节序,也就是大端模式。
在 boost::asio 库中,可以使用 boost::asio::detail::socket_ops::host_to_network_long() 和 boost::asio::detail::socket_ops::host_to_network_short() 函数将主机字节序转换为网络字节序。具体方法如下:
1 |
|
上述代码中,使用了 boost::asio::detail::socket_ops::host_to_network_long() 和 boost::asio::detail::socket_ops::host_to_network_short() 函数将主机字节序转换为网络字节序。
host_to_network_long() 函数将一个 32 位无符号整数从主机字节序转换为网络字节序,返回转换后的结果。host_to_network_short() 函数将一个 16 位无符号整数从主机字节序转换为网络字节序,返回转换后的结果。
在上述代码中,分别将 32 位和 16 位的主机字节序数值转换为网络字节序,并输出转换结果。需要注意的是,在使用这些函数时,应该确保输入参数和返回结果都是无符号整数类型,否则可能会出现错误。
同样的道理,我们只需要在服务器发送数据时,将数据长度转化为网络字节序,在接收数据时,将长度转为本机字节序。
在服务器的HandleRead函数里,添加对data_len的转换,将网络字节转为本地字节序
1 | //获取头部数据 |
- 在服务器的发送数据时会构造消息节点,构造消息节点时,将发送长度由本地字节序转化为网络字节序
1 | //用来构造发送节点 |
消息队列控制
- 发送时我们会将发送的消息放入队列里以保证发送的时序性,每个session都有一个发送队列,因为有的时候发送的频率过高会导致队列增大,所以要对队列的大小做限制,当队列大于指定数量的长度时,就丢弃要发送的数据包,以保证消息的快速收发。
1 | void CSession::Send(char* msg, int max_length) { |
protobuf配置和使用
portobuf简介
Protocol Buffers(简称 Protobuf)是一种轻便高效的序列化数据结构的协议,由 Google 开发。它可以用于将结构化数据序列化到二进制格式,并广泛用于数据存储、通信协议、配置文件等领域。
我们的逻辑是有类等抽象数据构成的,而tcp是面向字节流的,我们需要将类结构序列化为字符串来传输。
生成pb文件
- 要想使用protobuf的序列化功能,需要生成pb文件,pb文件包含了我们要序列化的类信息。我们先创建一个msg.proto,该文件用来定义我们要发送的类信息
1 | syntax = "proto3"; |
- 这个文件定义了一个名为Book的消息类型,包含三个字段:name、pages和price。其中每个字段都有一个数字标识符,用于标识该字段在二进制流中的位置。
- 我们使用protoc.exe 基于msg.proto生成我们要用的C++类
- 在proto所在文件夹执行如下命令:
1 | protoc --cpp_out=. ./msg.proto |
- —cpp_out= 表示指定要生成的pb文件所在的位置
./msg.proto 表示msg.proto所在的位置,因为我们是在msg.proto所在文件夹中执行的protoc命令,所以是当前路径即可。 - 执行后,会看到当前目录生成了msg.pb.h和msg.pb.cc两个文件,这两个文件就是我们要用到的头文件和cpp文件。
- 我们将这两个文件添加到项目里,然后在主函数中包含msg.pb.h,做如下测试
1 |
|
- 测试发现报错了

- 解决办法
1 | PROTOBUF_USE_DLLS |
运行后又发现无法找到dll文件
解决办法
将缺失的dll文件放在.exe的同级目录下
在网络编程中的应用
- 先为服务器定义一个用来通信的proto,根据你设计发送的数据来定
1 | syntax = "proto3"; |
- id代表消息id,data代表消息内容
- 我们用protoc生成对应的pb.h和pb.cc文件,方法见上
将proto,pb.cc,pb.h三个文件复制到我们之前的服务器项目里并且配置。
我们修改服务器接收数据和发送数据的逻辑
当服务器收到数据后,完成切包处理后,将信息反序列化为具体要使用的结构,打印相关的信息,然后再发送给客户端
服务端
1 | MsgData msgdata; |
- 客户端
- 同样的道理,客户端在发送的时候也利用protobuf进行消息的序列化,然后发给服务器
1 | MsgData msgdata; |
jsoncpp的使用与配置
简介
jsoncpp 是一个 C++ JSON 库,它提供了将 JSON 数据解析为 C++ 对象、将 C++ 对象序列化为 JSON 数据的功能。它支持所有主流操作系统(包括 Windows、Linux、Mac OS X 等),并且可以与常见编译器(包括 Visual Studio、GCC 等)兼容。
jsoncpp 库是以源代码的形式发布的,因此使用者需要自己构建和链接库文件。该库文件不依赖于第三方库,只需包含头文件即可使用。
jsoncpp 库的特点包括:
轻量级:JSON 解析器和序列化器都非常快速,不会占用太多的 CPU 和内存资源;
易于使用:提供简单的 API,易于理解和使用;
可靠性高:经过广泛测试,已被许多企业和开发者用于生产环境中;
开源免费:遵循 MIT 许可证发布,使用和修改均免费。
- 总之,jsoncpp 是一款优秀的 C++ JSON 库,它可以帮助你轻松地处理 JSON 数据,为你的项目带来便利和高效, 一般在前后端交互中用的多
配置参考我的csdn收藏
测试
1 |
|
网络编程中的应用
- 在客户端发送数据时对发送的数据进行序列化
1 | Json::Value root; |
- 我们可以在服务器收到数据时进行json反序列化
1 | Json::Reader reader; |
新版JSON库 nlohmann/json
asio粘包处理的简单方式
简单方式
- 之前我们介绍了通过async_read_some函数监听读事件,并且绑定了读事件的回调函数HandleRead
1 | _socket.async_read_some(boost::asio::buffer(_data, MAX_LENGTH), std::bind(&CSession::HandleRead, this, |
- async_read_some 这个函数的特点是只要对端发数据,服务器接收到数据,即使没有收全对端发送的数据也会触发HandleRead函数,所以我们会在HandleRead回调函数里判断接收的字节数,接收的数据可能不满足头部长度,可能大于头部长度但小于消息体的长度,可能大于消息体的长度,还可能大于多个消息体的长度,所以要切包等,这些逻辑写起来很复杂,所以我们可以通过读取指定字节数,直到读完这些字节才触发回调函数,那么可以采用async_read函数,这个函数指定读取指定字节数,只有完全读完才会触发回调函数。
获取头部数据
- 我们可以读取指定的头部长度,大小为HEAD_LENGTH字节数,只有读完HEAD_LENGTH字节才触发HandleReadHead函数
1 | void CSession::Start(){ |
- 这样我们可以直接在HandleReadHead函数内处理头部信息
1 | void CSession::HandleReadHead(const boost::system::error_code& error, size_t bytes_transferred, std::shared_ptr<CSession> shared_self) { |
- 接下来根据头部内存储的消息体长度,获取指定长度的消息体数据,所以再次调用async_read,指定读取_recv_msg_node->_total_len长度,然后触发HandleReadMsg函数
获取消息体
- HandleReadMsg函数内解析消息体,解析完成后打印收到的消息,接下来继续监听读事件,监听读取指定头部大小字节,触发HandleReadHead函数, 然后再在HandleReadHead内继续监听读事件,获取消息体长度数据后触发HandleReadMsg函数,从而达到循环监听的目的。
1 | void CSession::HandleReadMsg(const boost::system::error_code& error, size_t bytes_transferred, |
服务器逻辑层设计和消息完善
简介1
- 本文概述基于boost::asio实现的服务器逻辑层结构,并且完善之前设计的消息结构。因为为了简化粘包处理,我们简化了发送数据的结构,这次我们给出完整的消息设计,以及服务器架构设计。
服务器架构设计
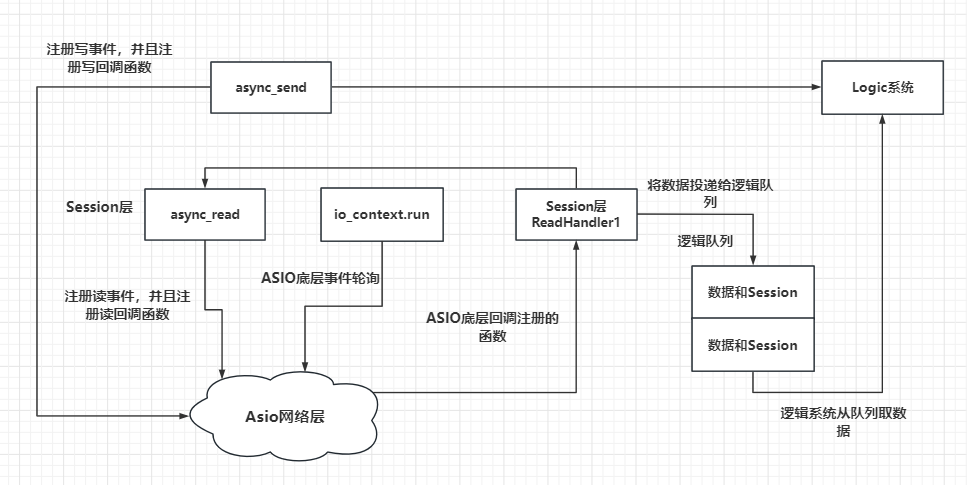
- 之前我们设计了Session(会话层),并且给大家讲述了Asio底层的通信过程,如下图
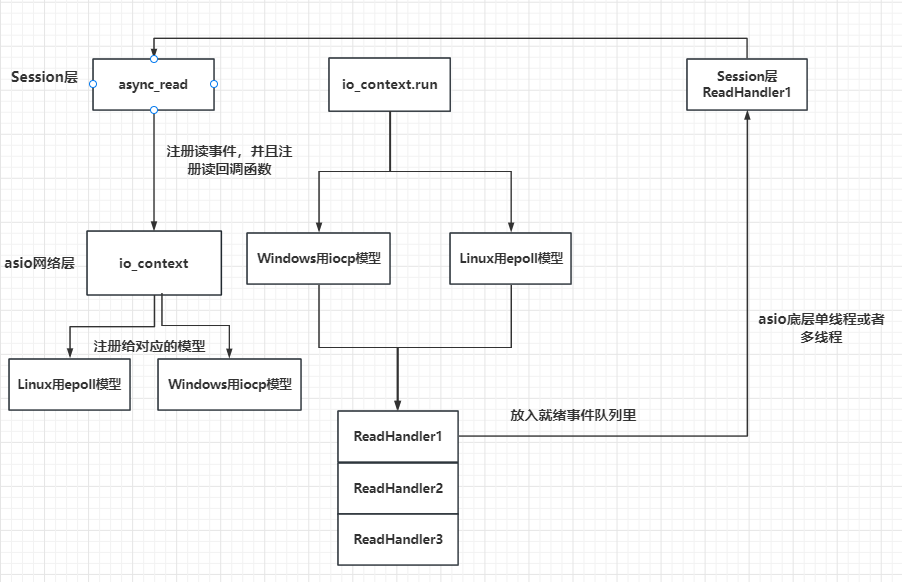
- 我们接下来要设计的服务器结构是这样的
消息头完善
- 我们之前的消息头仅包含数据域的长度,但是要进行逻辑处理,就需要传递一个id字段表示要处理的消息id,当然可以不在包头传id字段,将id序列化到消息体也是可以的,但是我们为了便于处理也便于回调逻辑层对应的函数,最好是将id写入包头。
- 之前我们设计的消息结构是这样的
- 现在改为这样
为了减少耦合和歧义,我们重新设计消息节点。
- MsgNode表示消息节点的基类,头部的消息用这个结构存储。
- RecvNode表示接收消息的节点。
- SendNode表示发送消息的节点。
我们将上述结构定义在MsgNode.h中
1 |
|
实现MsgNode
1 |
|
- SendNode发送节点构造时,先将id转为网络字节序,然后写入_data数据域。
- 然后将要发送数据的长度转为大端字节序,写入_data数据域,注意要偏移HEAD_ID_LEN长度。
- 最后将要发送的数据msg写入_data数据域,注意要偏移HEAD_ID_LEN+HEAD_DATA_LEN
Session类改写
完整的代码2
Session.h
1 |
|
Session.cpp
1 |
|
单例模式实现逻辑层设计
单例模板类
- 接下来我们实现一个单例模板类,因为服务器的逻辑处理需要单例模式,后期可能还会有一些模块的设计也需要单例模式,所以先实现一个单例模板类,然后其他想实现单例类只需要继承这个模板类即可。
1 |
|
其中的细节
- 因为是模板类,所以初始化的时候不能放在.cpp里,得放在.h里,并且又由于是模板类的静态成员,所以如果省略了 std::shared_ptr
,编译器将无法识别 _instance 的类型,并且无法进行类型推断。因此,在定义静态成员变量时,必须明确指明其类型。 得保证线程安全,可以使用C++11的once_flag 与 call_once,std::call_once 函数接受一个 std::once_flag 对象和一个函数作为参数,它会确保这个函数只被调用一次,实现原理是用加锁和一个标志位来实现,其逻辑与下属类似:
1
2
3
4
5
6
7
8static int* instance
bool flag = false;
if(flag) return instance;
std::mutex mtx;
std::lock_guard<std::mutex> lock(mtx);
if(flag) return instance;
instance = new int(2);
flag = true;
- 因为是模板类,所以初始化的时候不能放在.cpp里,得放在.h里,并且又由于是模板类的静态成员,所以如果省略了 std::shared_ptr
单例模式模板类将无参构造,拷贝构造,拷贝赋值都设定为protected属性,其他的类无法访问,其实也可以设置为私有属性。析构函数设置为公有的,其实设置为私有的更合理一点。
Singleton有一个static类型的属性_instance, 它是我们实际要开辟类型的智能指针类型。
s_flag是函数GetInstance内的局部静态变量,该变量在函数GetInstance第一次调用时被初始化。以后无论调用多少次GetInstance s_flag都不会被重复初始化,而且s_flag存在静态区,会随着进程结束而自动释放。
call_once只会调用一次,而且是线程安全的, 其内部的原理就是调用该函数时加锁,然后设置s_flag内部的标记,设置为已经初始化,执行lambda表达式逻辑初始化智能指针,然后解锁。第二次调用GetInstance 内部还会调用call_once, 只是call_once判断s_flag已经被初始化了就不执行初始化智能指针的操作了。
LogicSystem单例类
- 我们实现逻辑系统的单例类,继承自Singleton
,这样LogicSystem的构造函数和拷贝构造函数就都变为私有的了,因为基类的构造函数和拷贝构造函数都是私有的。另外LogicSystem也用了基类的成员_instance和GetInstance函数。从而达到单例效果。
1 |
|
- FunCallBack为要注册的回调函数类型,其参数为绘画类智能指针,消息id,以及消息内容
- _msg_que为逻辑队列
- _mutex 为保证逻辑队列安全的互斥量
- _consume表示消费者条件变量,用来控制当逻辑队列为空时保证线程暂时挂起等待,不要干扰其他线程。
- _fun_callbacks表示回调函数的map,根据id查找对应的逻辑处理函数。
- _worker_thread表示工作线程,用来从逻辑队列中取数据并执行回调函数。
- _b_stop表示收到外部的停止信号,逻辑类要中止工作线程并优雅退出。
- LogicNode定义在CSession.h中
1 | class LogicNode { |
- 其包含了会话类的智能指针,主要是为了实现伪闭包,防止session被释放。
其次包含了接收消息的节点类的智能指针。 - 实现如下:
1 | LogicNode::LogicNode(std::shared_ptr<CSession> session, std::shared_ptr<RecvNode> recvnode): _session(session), _recvnode(recvnode) |
- LogicSystem的构造函数如下
1 | LogicSystem::LogicSystem(): _b_stop(false) { |
- 构造函数中将停止信息初始化为false,注册消息处理函数并且启动了一个工作线程,工作线程执行DealMsg逻辑。
注册消息处理函数的逻辑如下:
1 | void LogicSystem::RegisterCallBacks() |
- MSG_HELLO_WORD定义在const.h中
1 | enum MSG_IDS { |
- MSG_HELLO_WORD表示消息id,HelloWordCallBack为对应的回调处理函数
1 | void LogicSystem::HelloWordCallBacks(std::shared_ptr<CSession> session, const short& msg_id, const std::string& msg_data) |
在HelloWordCallBack里我们根据消息id和收到的消息,做了相应的处理并且回应给客户端。
工作线程的处理函数DealMsg逻辑
1 | void LogicSystem::DealMsg() |
- DealMsg逻辑中初始化了一个unique_lock,主要是用来控制队列安全,并且配合条件变量可以随时解锁。lock_guard不具备解锁功能,所以此处用unique_lock。
- 我们判断队列为空,并且不是停止状态,就挂起线程。否则继续执行之后的逻辑,如果_b_stop为true,说明处于停服状态,则将队列中未处理的消息全部处理完然后退出循环。如果_b_stop未false,则说明没有停服,是consumer发送的激活信号激活了线程,则继续取队列中的数据处理。
- LogicSystem的析构函数需要等待工作线程处理完再退出,但是工作线程可能处于挂起状态,所以要发送一个激活信号唤醒工作线程。并且将_b_stop标记设置为true。
1 | LogicSystem::~LogicSystem(){ |
- 因为网络层收到消息后我们需要将消息投递给逻辑队列进行处理,那么LogicSystem就要封装一个投递函数
1 | void LogicSystem::PostMsgToQue(std::shared_ptr<LogicNode> msg) |
- 在Session收到数据时这样调用
1 | LogicSystem::GetInstance()->PostMsgToQue(make_shared<LogicNode>(shared_from_this(), _recv_msg_node)); |
LogicSystem 完整代码
头文件
1 |
|
实现
1 |
|
服务器优雅退出
退出方式1:开辟线程,让服务器运行在线程中并接受退出信号退出
1 |
|
退出方式2:使用asio底层异步等待函数
1 |
|
总结
- 两种方式都对服务器进行了优雅的退出
asio多线程模型IOServicePool
简介
- 前面的设计,我们对asio的使用都是单线程模式,为了提升网络io并发处理的效率,这一次我们设计多线程模式下asio的使用方式。总体来说asio有两个多线程模型,第一个是启动多个线程,每个线程管理一个iocontext。第二种是只启动一个iocontext,被多个线程共享,后面的文章会对比两个模式的区别,这里先介绍第一种模式,多个线程,每个线程管理独立的iocontext服务。
单线程和多线程对比
- 之前的单线程模式图如下
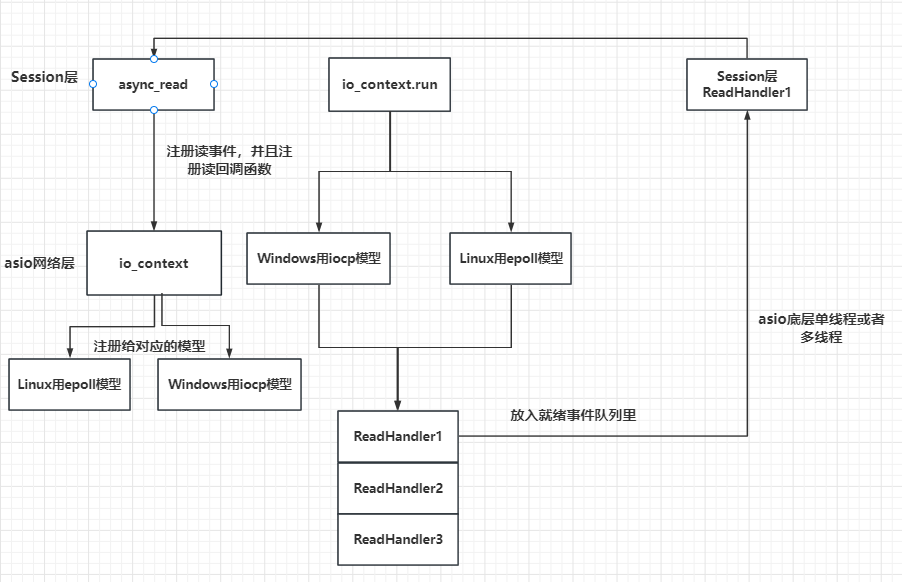
- 我们设计的IOServicePool类型的多线程模型如下:
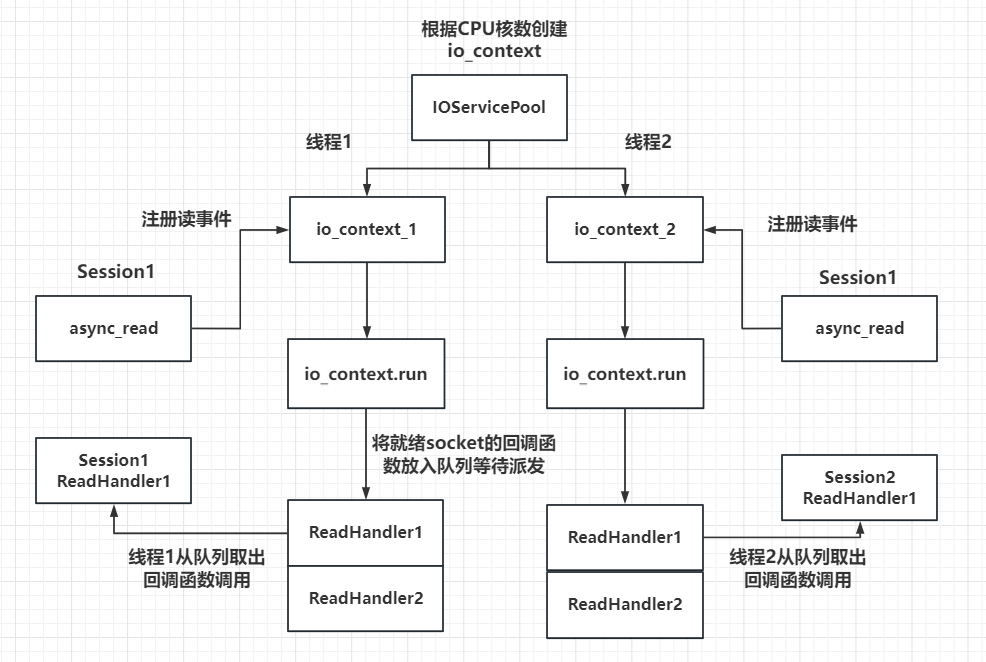
- IOServicePool多线程模式特点
- 每一个io_context跑在不同的线程里,所以同一个socket会被注册在同一个io_context里,它的回调函数也会被单独的一个线程回调,那么对于同一个socket,他的回调函数每次触发都是在同一个线程里,就不会有线程安全问题,网络io层面上的并发是线程安全的。
- 但是对于不同的socket,回调函数的触发可能是同一个线程(两个socket被分配到同一个io_context),也可能不是同一个线程(两个socket被分配到不同的io_context里)。所以如果两个socket对应的上层逻辑处理,如果有交互或者访问共享区,会存在线程安全问题。比如socket1代表玩家1,socket2代表玩家2,玩家1和玩家2在逻辑层存在交互,比如两个玩家都在做工会任务,他们属于同一个工会,工会积分的增加就是共享区的数据,需要保证线程安全。可以通过加锁或者逻辑队列的方式解决安全问题,我们目前采取了后者。
- 多线程相比单线程,极大的提高了并发能力,因为单线程仅有一个io_context服务用来监听读写事件,就绪后回调函数在一个线程里串行调用, 如果一个回调函数的调用时间较长肯定会影响后续的函数调用,毕竟是穿行调用。而采用多线程方式,可以在一定程度上减少前一个逻辑调用影响下一个调用的情况,比如两个socket被部署到不同的iocontext上,但是当两个socket部署到同一个iocontext上时仍然存在调用时间影响的问题。不过我们已经通过逻辑队列的方式将网络线程和逻辑线程解耦合了,不会出现前一个调用时间影响下一个回调触发的问题。
IOServicePool实现
- 在使用拷贝构造的时候参数列表的&是必须的,原因:这不仅仅只是为了减少一次构造成本,更重要是为了避免递归构造
1 | Pool(const Pool x); |
- 以上就会有循环构造的情况,p2传给参数列表的时候又要调用拷贝构造 Pool x = p2, 之后又要进行拷贝构造,如此循环
同时一定要判断拷贝的是不是自己这种情况
IOServicePool本质上是一个线程池,基本功能就是根据构造函数传入的数量创建n个线程和iocontext,然后每个线程跑一个iocontext,这样就可以并发处理不同iocontext读写事件了。
IOServicePool的声明:
1 |
|
- _ioServices是一个IOService的vector变量,用来存储初始化的多个IOService。
- WorkPtr是boost::asio::io_context::work类型的unique指针。
在实际使用中,我们通常会将一些异步操作提交给io_context进行处理,然后该操作会被异步执行,而不会立即返回结果。如果没有其他任务需要执行,那么io_context就会停止工作,导致所有正在进行的异步操作都被取消。这时,我们需要使用boost::asio::io_context::work对象来防止io_context停止工作。
- boost::asio::io_context::work的作用是持有一个指向io_context的引用,并通过创建一个“工作”项来保证io_context不会停止工作,直到work对象被销毁或者调用reset()方法为止。当所有异步操作完成后,程序可以使用work.reset()方法来释放io_context,从而让其正常退出。
- _threads是一个线程vector,管理我们开辟的所有线程。
- _nextIOService是一个轮询索引,我们用最简单的轮询算法为每个新创建的连接分配io_context.
- 因为IOServicePool不允许被copy构造,所以我们将其拷贝构造和拷贝复制函数置为delete
实现
1 |
|
优雅退出
- IOServicePool多线程服务器退出时,需要捕获退出信号如SIGINT,SIGTERM等,将退出信号和一个iocontext绑定,当收到退出信号时,我们将IOServicePool停止,并且停止iocontext即可。
1 | int main() |
asio多线程模式IOThreadPool
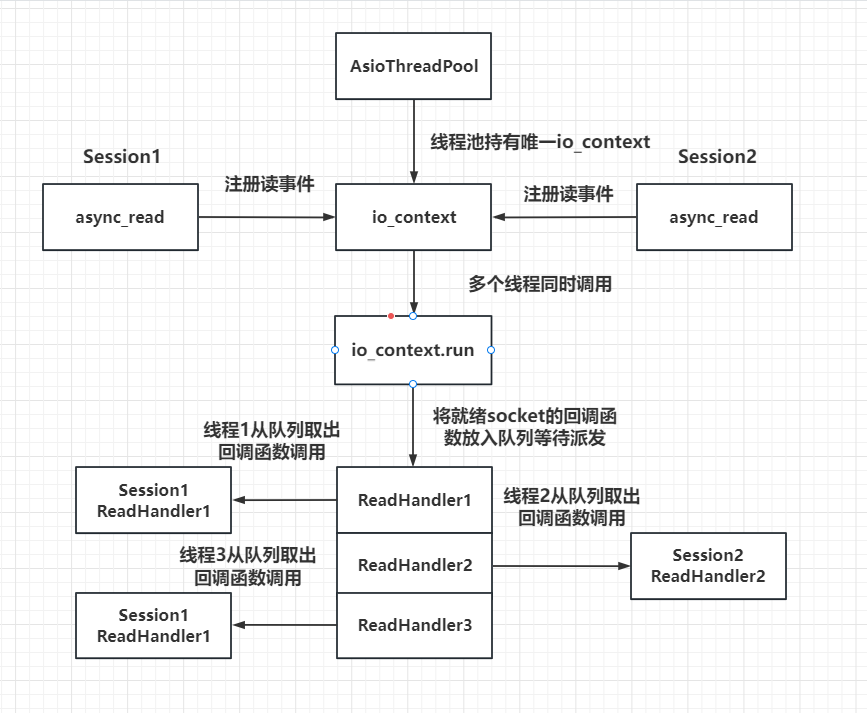
- 今天给大家介绍asio多线程模式的第二种,之前我们介绍了IOServicePool的方式,一个IOServicePool开启n个线程和n个iocontext,每个线程内独立运行iocontext, 各个iocontext监听各自绑定的socket是否就绪,如果就绪就在各自线程里触发回调函数。为避免线程安全问题,我们将网络数据封装为逻辑包投递给逻辑系统,逻辑系统有一个单独线程处理,这样将网络IO和逻辑处理解耦合,极大的提高了服务器IO层面的吞吐率。这一次介绍的另一种多线程模式IOThreadPool,我们只初始化一个iocontext用来监听服务器的读写事件,包括新连接到来的监听也用这个iocontext。只是我们让iocontext.run在多个线程中调用,这样回调函数就会被不同的线程触发,从这个角度看回调函数被并发调用了。
结构图
- 线程池模式的多线程模型调度结构图,如下
先实现IOThreadPool
IOThreadPool 头文件
1 |
|
- IOThreadPool继承了Singleton
,实现了一个函数GetIOService获取iocontext
IOThreadPool 实现
1 |
|
构造函数中实现了一个线程池,线程池里每个线程都会运行_service.run函数,_service.run函数内部就是从iocp或者epoll获取就绪描述符和绑定的回调函数,进而调用回调函数,因为回调函数是在不同的线程里调用的,所以会存在不同的线程调用同一个socket的回调函数的情况。
_service.run 内部在Linux环境下调用的是epoll_wait返回所有就绪的描述符列表,在windows上会循环调用GetQueuedCompletionStatus函数返回就绪的描述符,二者原理类似,进而通过描述符找到对应的注册的回调函数,然后调用回调函数。
iocp的流程是这样的
1 | IOCP的使用主要分为以下几步: |
epoll流程是这样的
1 | 1 调用epoll_creat在内核中创建一张epoll表 |
隐患
- IOThreadPool模式有一个隐患,同一个socket的就绪后,触发的回调函数可能在不同的线程里,比如第一次是在线程1,第二次是在线程3,如果这两次触发间隔时间不大,那么很可能出现不同线程并发访问数据的情况,比如在处理读事件时,第一次回调触发后我们从socket的接收缓冲区读数据出来,第二次回调触发,还是从socket的接收缓冲区读数据,就会造成两个线程同时从socket中读数据的情况,会造成数据混乱。
利用strand改进
- 对于多线程触发回调函数的情况,我们可以利用asio提供的串行类strand封装一下,这样就可以被串行调用了,其基本原理就是在线程各自调用函数时取消了直接调用的方式,而是利用一个strand类型的对象将要调用的函数投递到strand管理的队列中,再由一个统一的线程调用回调函数,调用是串行的,解决了线程并发带来的安全问题。

图中当socket就绪后并不是由多个线程调用每个socket注册的回调函数,而是将回调函数投递给strand管理的队列,再由strand统一调度派发。
为了让回调函数被派发到strand的队列,我们只需要在注册回调函数时加一层strand的包装即可。
在CSession类中添加一个成员变量
1 | strand<io_context::executor_type> _strand; |
- CSession构造函数
1 | CSession::CSession(boost::asio::io_context& io_context, CServer* server): |
可以看到_strand的初始化是放在初始化列表里,利用io_context.get_executor()返回的执行器构造strand。
因为在asio中无论iocontext还是strand,底层都是通过executor调度的,我们将他理解为调度器就可以了,如果多个iocontext和strand的调度器是一个,那他们的消息派发统一由这个调度器执行。
我们利用iocontext的调度器构造strand,这样他们统一由一个调度器管理。在绑定回调函数的调度器时,我们选择strand绑定即可。
比如我们在Start函数里添加绑定 ,将回调函数的调用者绑定为_strand
1 | void CSession::Start(){ |
- 同样的道理,在所有收发的地方,都将调度器绑定为_strand, 比如发送部分我们需要修改为如下
1 | auto& msgnode = _send_que.front(); |
- 修改main函数
1 |
|
CSession代码
- 改动了将回调函数绑定到_strand的处理器里上
1 |
|
性能对比
为了比较两种服务器多线程模式的性能,我们还是利用之前测试的客户端,客户端每隔10ms建立一个连接,总共建立100个连接,每个连接收发500次,总计10万个数据包,测试一下性能。
客户端测试代码如下
1 |
|
- 测试得出今天实现的多线程模式较之前的IOServicePool版本慢了7秒
取舍
- 实际的生产和开发中,我们尽可能利用C++特性,使用多核的优势,将iocontext分布在不同的线程中效率更可取一点(也就是第一种),但也要防止线程过多导致cpu切换带来的时间片开销,所以尽量让开辟的线程数小于或等于cpu的核数,从而利用多核优势。
boost::asio协程实现并发服务器
简介
- 之前介绍了asio服务器并发编程的几种模型,包括单线程,多线程IOServicePool,多线程IOThreadPool等,今天带着大家利用asio协程实现并发服务器。利用协程实现并发程序有两个好处
- 将回调函数改写为顺序调用,提高开发效率。
- 协程调度比线程调度更轻量化,因为协程是运行在用户空间的,线程切换需要在用户空间和内核空间切换。
协程案例
- asio官网提供了一个协程并发编程的案例,我们列举一下
1 |
|
- 我们用awaitable
声明了一个函数,那么这个函数就变为可等待的函数了,比如listener被添加awaitable 之后,就可以被协程调用和等待了。 - co_spawn表示启动一个协程,参数分别为调度器,执行的函数,以及启动方式, 比如我们启动了一个协程,deatched表示将协程对象分离出来,这种启动方式可以启动多个协程,他们都是独立的,如何调度取决于调度器,在用户的感知上更像是线程调度的模式,类似于并发运行,其实底层都是串行的。
1 | co_spawn(io_context, listener(), detached); |
我们启动了一个协程,执行listener中的逻辑,listener内部co_await 等待 acceptor接收连接,如果没有连接到来则挂起协程。执行之后的io_context.run()逻辑。所以协程实际上是在一个线程中串行调度的,只是感知上像是并发而已。
- 当acceptor接收到连接后,继续调用co_spawn启动一个协程,用来执行echo逻辑。echo逻辑里也是通过co_wait的方式接收和发送数据的,如果对端不发数据,执行echo的协程就会挂起,另一个协程启动,继续接收新的连接。当没有连接到来,接收新连接的协程挂起,如果所有协程都挂起,则等待新的就绪事件(对端发数据,或者新连接)到来唤醒。
- 使用协程的时候有没有 co_await的区别
- 不使用 co_await:
如果不使用 co_await,acceptor.async_accept 将会返回一个可等待对象,但不会在此处等待该对象的完成。相反,它将立即返回,继续执行后续的代码,而不管是否有连接请求到来。这可能导致后续的代码在没有获得有效的 tcp::socket 对象的情况下进行执行,从而产生错误或未定义的行为。- 使用 co_await:
当使用 co_await 时,协程会在 acceptor.async_accept 返回的可等待对象完成之前挂起,并暂停当前协程的执行。这意味着协程会等待连接请求到来,并在收到请求后继续执行。在这种情况下,async_accept 返回的 tcp::socket 对象将被分配给变量 sock,以便后续与客户端进行通信。
- 使用 co_await:
- 不使用 co_await:
完整并发服务器
- 由于服务器发送数据或者请求比较频繁,所以考虑设计为不用协程而用线程的方式,这样相比协程可以增加效率,而且发送可能会在其他线程
- 我们可以利用协程改进服务器编码流程,用一个iocontext管理绑定acceptor用来接收新的连接,再用一个iocontext或以IOServicePool的方式管理连接的收发操作,在每个连接的接收数据时改为启动一个协程,通过顺序的方式读取收到的数据
AsiIOServicePool
AsioIOServicePool头文件
1 |
|
AsioIOServicePool实现
1 |
|
cosnt.h
- 专门用来存放常量
1 |
|
CServer
CServer头文件
1 |
|
CServer实现
1 |
|
CSession
CSession.h
1 |
|
CSession实现
1 |
|
LogicSystem
LogicSystem头文件
1 |
|
LogicSystem实现
1 |
|
MsgNode
MsgNode头文件
1 |
|
MsgNode 实现
1 |
|
使用asio实现http服务器
简介
- 前文介绍了asio如何实现并发的长连接tcp服务器,今天介绍如何实现http服务器,在介绍实现http服务器之前,需要讲述下http报文头的格式,其实http报文头的格式就是为了避免我们之前提到的粘包现象,告诉服务器一个数据包的开始和结尾,并在包头里标识请求的类型如get或post等信息。
Http包头信息
- 一个标准的HTTP报文头通常由请求头和响应头两部分组成。
HTTP请求头
HTTP请求头包括以下字段:
- Request-line:包含用于描述请求类型、要访问的资源以及所使用的HTTP版本的信息。
- Host:指定被请求资源的主机名或IP地址和端口号。
- Accept:指定客户端能够接收的媒体类型列表,用逗号分隔,例如 text/plain, text/html。
- User-Agent:客户端使用的浏览器类型和版本号,供服务器统计用户代理信息。
- Cookie:如果请求中包含cookie信息,则通过这个字段将cookie信息发送给Web服务器。
- Connection:表示是否需要持久连接(keep-alive)
比如下面就是一个实际应用
1 | GET /index.html HTTP/1.1 |
- Request-line:指定使用GET方法请求/index.html资源,并使用HTTP/1.1协议版本。
- Host:指定被请求资源所在主机名或IP地址和端口号。
- Accept:客户端期望接收的媒体类型列表,本例中指定了text/html、application/xhtml+xml和任意类型的文件(/)。
- User-Agent:客户端浏览器类型和版本号。
- Cookie:客户端发送给服务器的cookie信息。
- Connection:客户端请求后是否需要保持长连接。
HTTP响应头
HTTP响应头包括以下字段:
- Status-line:包含协议版本、状态码和状态消息。
- Content-Type:响应体的MIME类型。
- Content-Length:响应体的字节数。
- Set-Cookie:服务器向客户端发送cookie信息时使用该字段。
- Server:服务器类型和版本号。
- Connection:表示是否需要保持长连接(keep-alive)。
在实际的HTTP报文头中,还可以包含其他可选字段。
- 如下就是一个例子
1 | HTTP/1.1 200 OK |
- Status-line:指定HTTP协议版本、状态码和状态消息。
- Content-Type:指定响应体的MIME类型及字符编码格式。
- Content-Length:指定响应体的字节数。
- Set-Cookie:服务器向客户端发送cookie信息时使用该字段。
- Server:服务器类型和版本号。
Connection:服务器是否需要保持长连接。
使用beast网络库实现http服务器
简介
- 前面的几篇文章已经介绍了如何使用asio搭建高并发的tcp服务器,以及http服务器。但是纯手写http服务器太麻烦了,有网络库beast已经帮我们实现了。这一期讲讲如何使用beast实现一个http服务器。
连接类
- 我们先实现http_server函数
1 | void http_server(boost::asio::ip::tcp::acceptor& acceptor, boost::asio::ip::tcp::socket& socket) { |
http_server中添加了异步接收连接的逻辑,当有新的连接到来时创建http_connection,然后启动服务,新连接监听对端数据。接下来http_server继续监听对端的新连接。
连接类http_connection里实现了start函数监听对端数据
1 | void Start() { |
- 处理读请求,将读到的数据存储再成员变量request_中,然后调用process_request处理请求
1 | //实现读请求 |
- check_deadline主要时用来检测超时,当超过一定时间后自动关闭连接,因为http请求时短链接
1 | // 检测定时器 |
- process_request函数中区分请求的类型,进行不同类型的处理如post还是get请求
1 | void process_request() { |
- create_response函数中解析了不同的路由处理get请求
1 | void create_get_response() { |
- create_post_response处理了post请求中的一部分路由
1 | void create_post_response() { |
- write_response发送请求
1 | void write_response() { |
完整代码
1 |
|
beast网络库实现websocket服务器
简介
- 使用beast网络库实现websocket服务器,一般来说websocket是一个长连接的协议,但是自动包含了解包处理,当我们在浏览器输入一个http请求时如果是以ws开头的如ws://127.0.0.1:9501就是请求本地9501端口的websocket服务器处理。而beast为我们提供了websocket的处理方案,我们可以在http服务器的基础上升级协议为websocket,处理部分websocket请求。如果服务器收到的是普通的http请求则按照http请求处理。我们可以从官方文档中按照示例逐步搭建websocket服务器。
构造websocket
开发的websocket代码
Connection.h
1 |
|
Connection.cpp
1 |
|
ConnectionMgr.h
1 |
|
ConnectionMgr.cpp
1 |
|
WebSocketServer.h
1 |
|
WebSocketServer.cpp
1 |
|
main.cpp
1 |
|
总结
头文件预编译的时候不要出现父子的情况,也就是说beast.hpp 包含了 beast/core,两个一起被编译就会出现问题
一旦声明构造函数,就要显示写出构造函数,因为他不会提供默认构造函数
gRPC的使用
- 有关gRPC的配置及下载等请查阅https://llfc.club/articlepage?id=2QYdExDcUDazjD6ZKNjs8KLcyAp
gRPC客户端
1 |
|
- 客户端创建了一个channel,然后调用NewStub生成stub,接下来就可以发送数据了,下面是运行的效果
- 其中stub是用来远程调用服务端的必要东西
gRPC服务端
1 |
|
- GreeterServiceImpl 继承自 Greeter::Service,重写了SayHello函数,当收到客户端发送的SayHello请求后执行重写函数功能的逻辑。
