go底层知识
目录
go的底层相关知识
go的类型系统
- 首先接口类型是无效的方法接收者,要理解这句话就要知道什么是方法?,方法是与特定类型关联的函数,那什么是方法接收者,方法接收者:方法有一个接收者(receiver),它指定了这个方法属于哪个类型。
1 | // Person 就是方法接受者, 这就是定义了Person结构体的一种方法 |
- 理解方法接收者后,因为接口他只是定义了方法,本身不能实现方法,也就不能作为方法接收者
类型元数据
- 不管是自定义类型还是内置类型,都有相应的类型元数据,类型元数据用来记录一些信息,例如:类型名称,大小,类型边界 等信息
所以底层会有一个_type结构体来存储类型元数据,其结构体如下:
1 | type _type struct { |
以上的信息作为元数据的头部,其下面还会有一些其他的描述数据,例如切片元数据的类型元数据结构如下:
1 | type slicetype struct { |
elem就是其中一种描述数据
- 对于自定义类型来说,其类型还会有一个uncommontype结构体字段,其结构体如下:
1 | type uncommontype struct { |
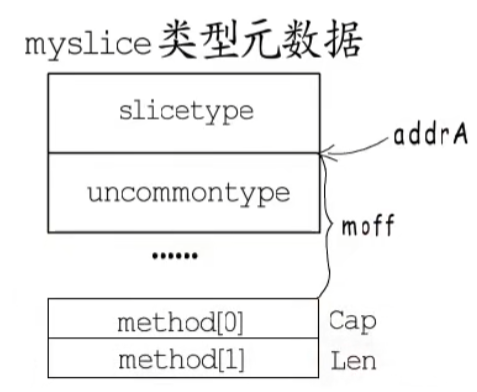
详细讲讲方法列表偏移值的作用,这个偏移值就是uncommontype结构体的moff字段,加上uncommontype的地址就是方法列表所在位置,如图
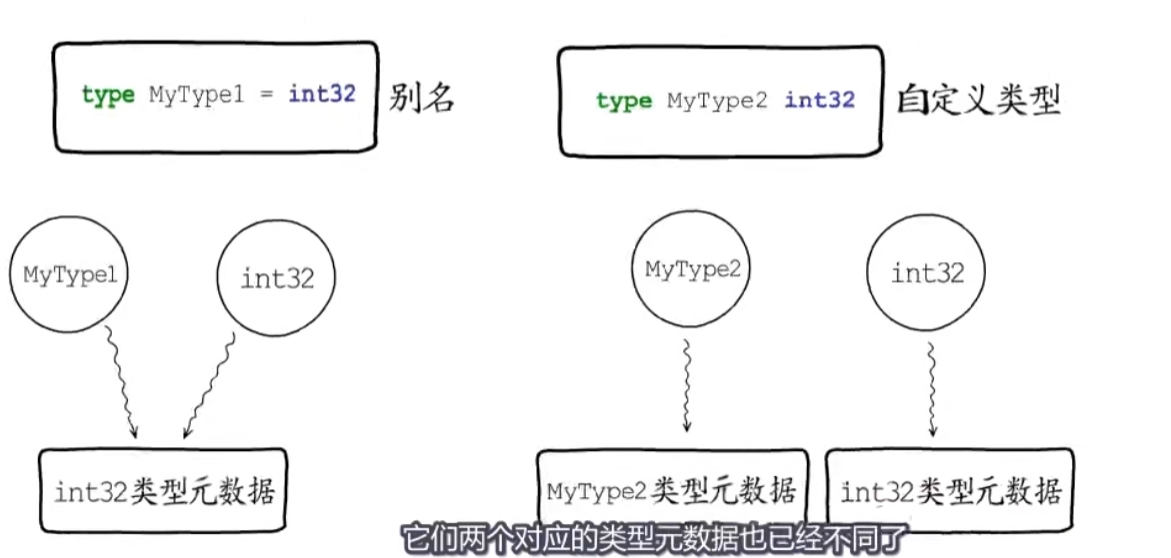
- type 的两种不同用法的区别:
go接口底层
空接口底层
- 因为空接口可以指向任意类型,所以在底层只需要知道指向的地址在哪,以及指向的是什么类型就行,所以其底层大概如下:

- 赋值前后的变化:
- 赋值前:两个字段都是nil
- 赋值后:data字段指向实际地址,_type执行类型元数据
- 赋值前:两个字段都是nil



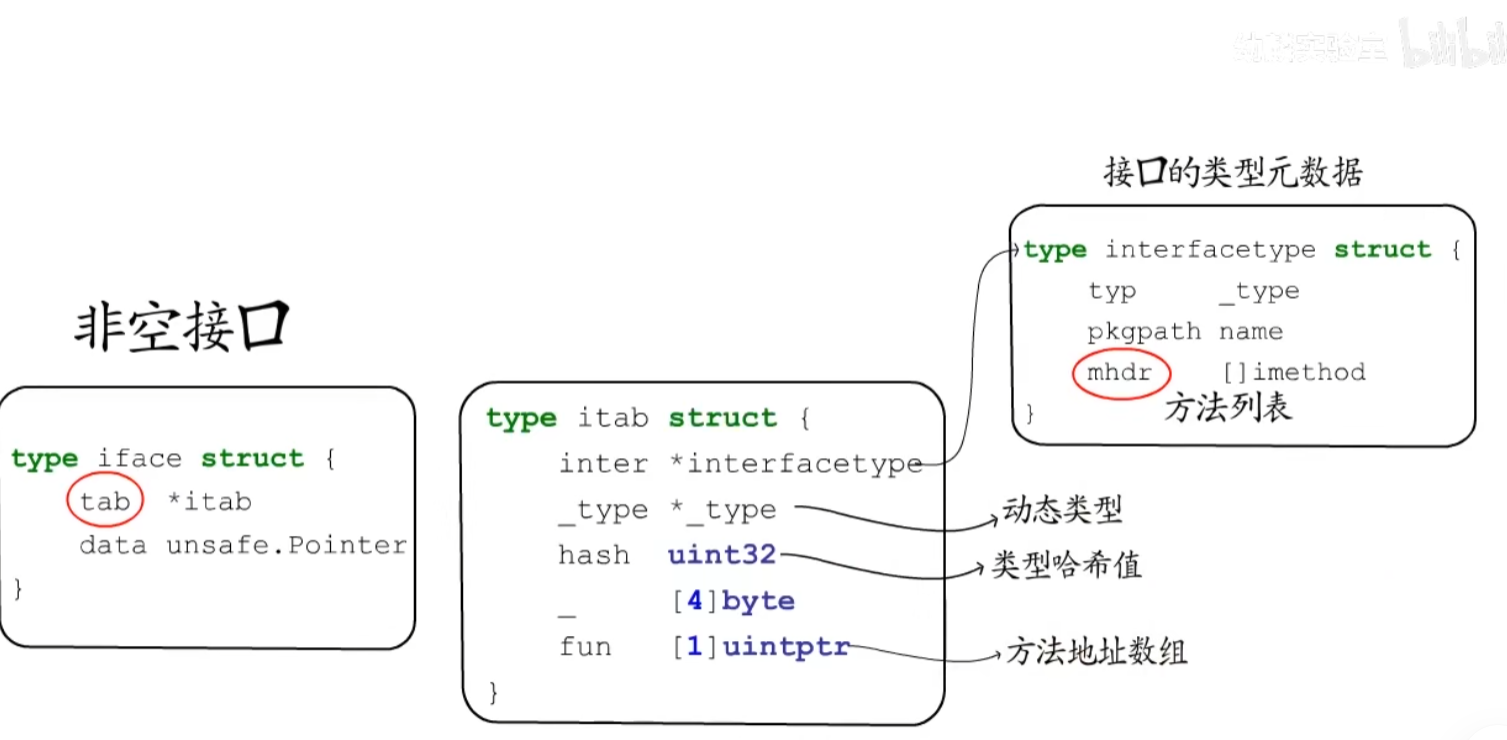
非空接口底层
-
非空接口(有方法的接口)底层的结构如下:
-
非空接口赋值前后的变化:
- 赋值前:两个字段都是nil
- 赋值后:
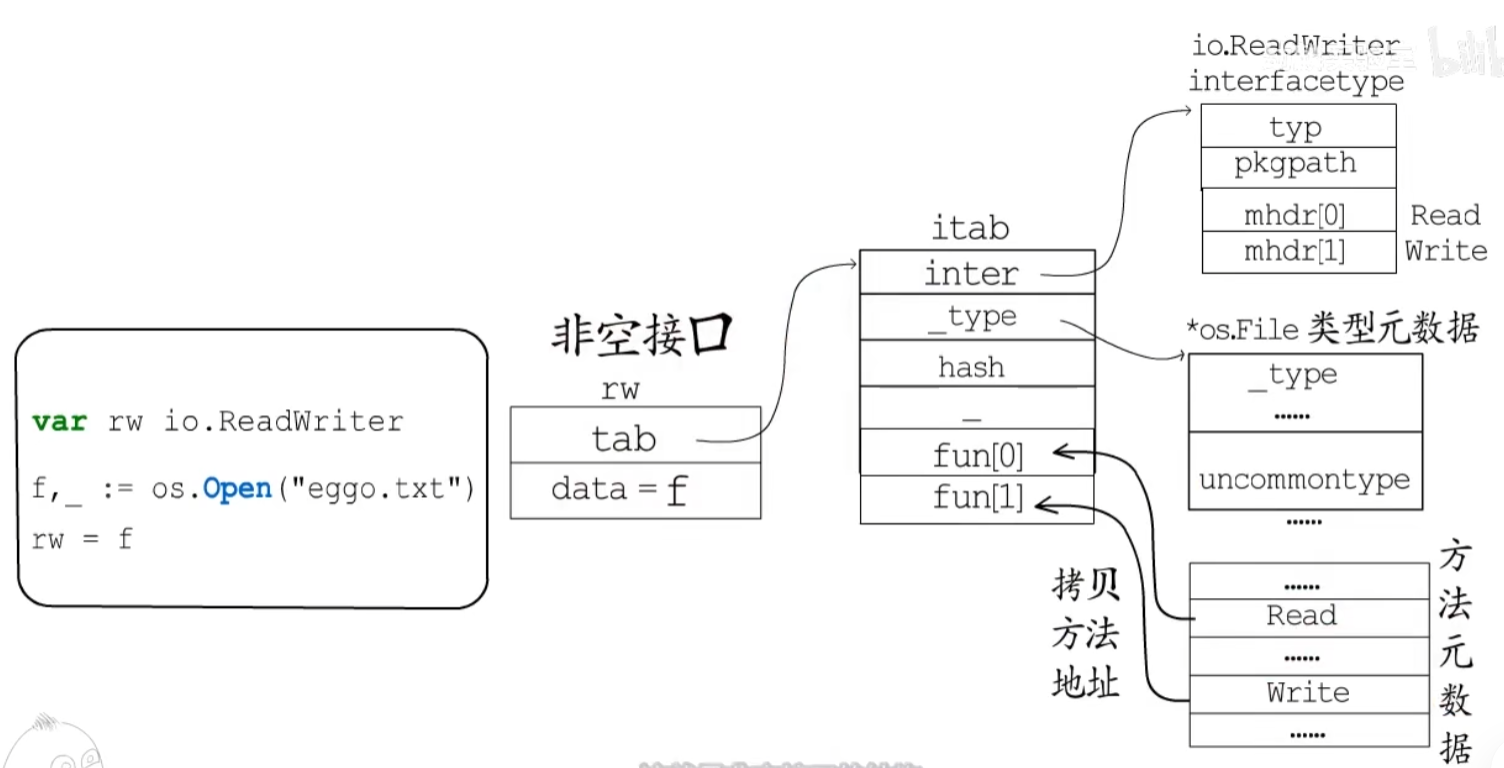
对上图的解释:
首先data字段就是指向实际的地址,tab字段就是接口的相关信息,从上到下分别是inter(指向的是对应接口类型的元数据)
_type(指向*os.File类型元数据),hash为快速判断是否相等的哈希值,然后是两个空接口的字段,分别是两个空接口的类型元数据及hash值,hash是用来快速判断是否相等。
fun则是一个数字,里面存的是拷贝过来的方法,这样就不需要反复去元数据中查找了,并且能快速定位到方法
其次对于itab只要知道了inter和_type就知道了itab的类型,也就是说inter和_type可以唯一确定一个itab,因此在底层有缓存机制
在go中会把用到的itab结构体缓存起来,并且创建以接口类型和动态类型为key,指向itab的指针为值的哈希表,需要itab时会首先在这个哈希表(接口类型哈希值与动态类型哈希值进行异或得到哈希表的哈希值)中查找,没有的话就创建一个itab结构体并加入到哈希表中
类型断言是如何工作的
go的堆栈和逃逸分析
相比于把内存分配到堆中,分配到栈中优势更明显。Go语言也是这么做的:Go编译器会尽可能将变量分配到到栈上。但是,当编译器无法证明函数返回的变量有没有被引用时,编译器就必须在堆上分配该变量,以此避免悬挂指针(dangling pointer)的问题。另外,如果局部变量占用内存非常大,也会将其分配在堆上。
问题:go是如何确定内存是分配到栈上还是堆上?
答案:逃逸分析
逃逸分析
- 什么是逃逸分析:编译器通过逃逸分析技术去选择堆或者栈,逃逸分析的基本思想如下:检查变量的生命周期是否是完全可知的,如果通过检查,则在栈上分配。否则,就是所谓的逃逸,必须在堆上进行分配。
逃逸分析的基本原则
- 不同于JAVA JVM的运行时逃逸分析,Go的逃逸分析是在编译期完成的:编译期无法确定的参数类型必定放到堆中;
- 如果变量在函数外部存在引用,则必定放在堆中;
- 如果变量占用内存较大时,则优先放到堆中;
- 如果变量在函数外部没有引用,则优先放到栈中;
逃逸分析举例
我们使用这个命令来查看逃逸分析的结果: go build -gcflags ‘-m -m -l’
- 参数类型是interface类型
1 | pacakge main |
运行结果
这段代码就输出了 a escapes to heap
原因分析
因为Println的参数类型是interface,编译器无法确定它的具体类型,因此必须在堆上分配。
- 变量在外部存在引用
1 | package main |
运行结果
这段代码就输出了moved to head: a
原因分析
变量a在函数外部存在引用。
我们来分析一下执行过程:当函数执行完毕,对应的栈帧就被销毁,但是引用已经被返回到函数之外。如果这时外部通过引用地址取值,虽然地址还在,但是这块内存已经被释放回收了,这就是非法内存。
为了避免上述非法内存的情况,在这种情况下变量的内存分配必须分配到堆上
- 变量占用内存较大
1 | package main |
运行结果
这段代码就输出了make([]int, 10000, 10000) escapes to heap
原因分析
我们定义了一个容量为10000的int类型切片,发生了逃逸,内存分配到了堆上(heap)。
- 变量大小不确定的时候也会分配在堆上
1 | package main |
运行结果
这段代码就输出了make([]int, l, l) escapes to heap
原因分析
我们虽然在代码段中给变量 l 赋值了1,但是编译期间只能识别到初始化int类型切片时,传入的长度和容量是变量l,编译期并不能确定变量l的值,所以发生了逃逸,会把内存分配到堆中。
go的字符串
-
在go中字符串是以字符串所占字节数结尾的,例如:
- Hello 字符串 那么它结尾就会存5
- 如果是Hello世界,那么他结尾就是5+3+3=11
-
一个字符串所占用的内存空间为16字节,Why?
首先字符串是一个类型,一个字符串由一个指向字符串值的指针和一个int型数据组成,这个int数据表示字符串值所占的实际字节数,所以一个字符串所占用的内存为8(指针的大小)+8(int的大小)=16字节。 -
在go中字符串是存在只读内存段中,不能对字符串内部进行修改,如果想要修改可以转换成byteSlice切片,但这样会导致原来的内存失效,数据被拷贝到新内存中,但是也可以通过使用unsafe包和slice结构时就可以做到使用原来的内存,也就导致依然无法修改内部内容
go的切片底层实现
-
slice 切片底层一共有三个数据,一个表示data数据指针,一个表示长度,一个表示容量
-
给slice切片开辟的时候有两种方式,第一种方式用**make(in[],2,5)**这样会开辟一个有5容量的底层数组,并且默认赋值0,再执行append操作就会在第三个位置插入,然后长度改为3, 如图:
-
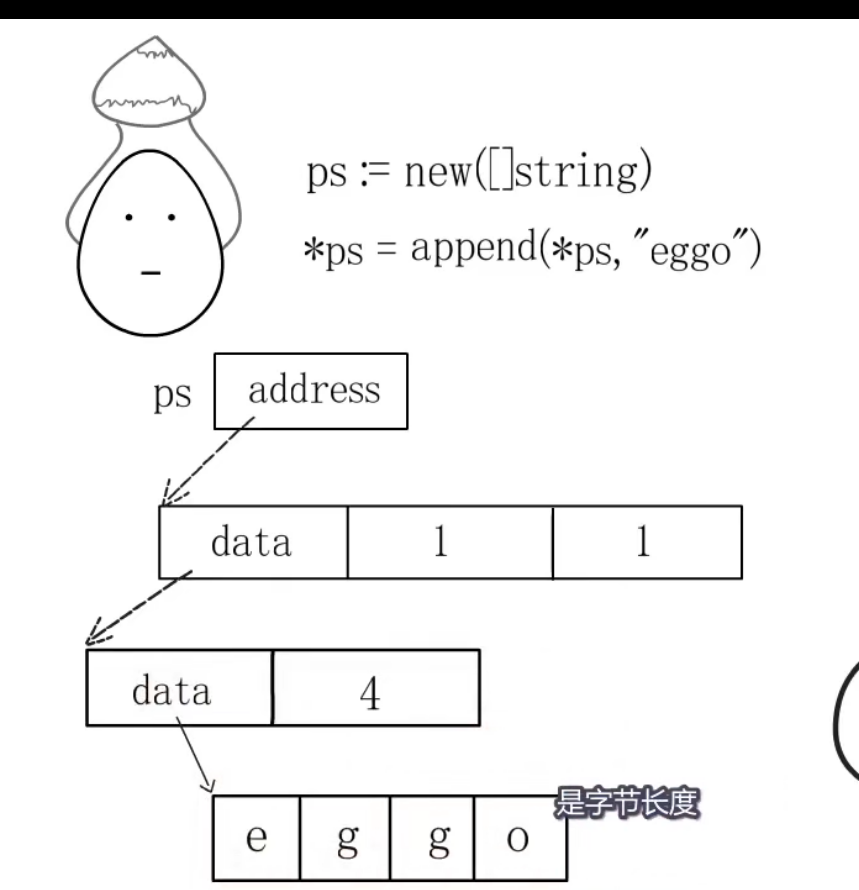
另一种方式使用new,使用new的话不会开辟数组空间,且返回的是一个切片的起始地址,只有通过append之后触发了扩容机制,扩容底层数组,导致了地址的分配
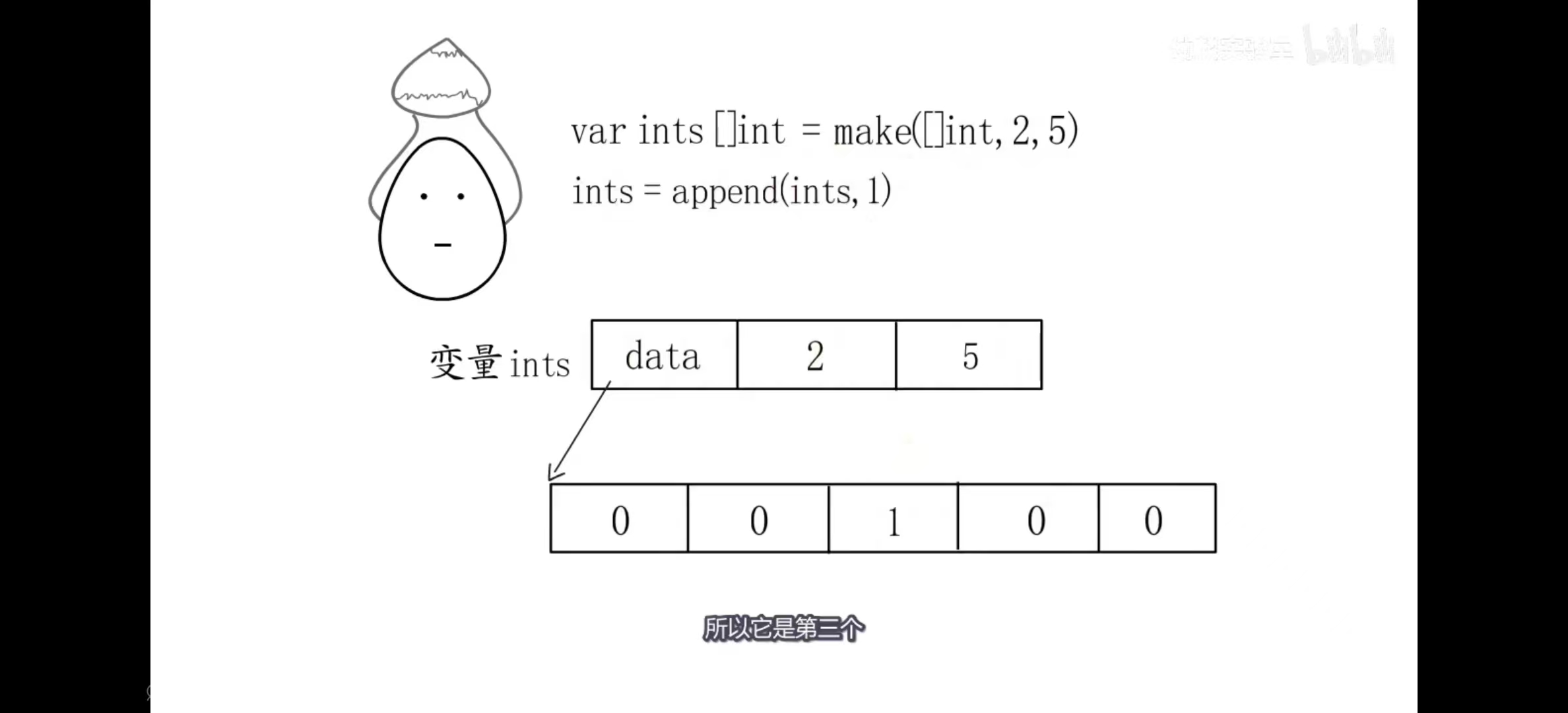
- 对于以下情况
1 | arr := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} // 开辟一个数组 |
这样的话,s1和s2的底层数组指向的都是数组的对应地址,如图所示:

所以如果修改s1或者s2的元素,会影响到arr的元素,因为他们指向的是同一个数组的不同部分。同时s1的容量是9长度是3而s2的长度和容量都是3
但是如果向s2append新元素,就会开辟新空间,把数组的应位置的元素拷贝到新空间,由于容量不够就会触发扩容机制,会2倍扩容,之后会把新元素追加到后面,如图所示:

go中int占8字节
1.18之前的扩容规则
-
在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
-
如果期望容量大于当前容量的两倍就会使用期望容量;
-
如果当前切片的长度小于 1024 就会将容量翻倍;
-
如果当前切片的长度大于等于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;

记录内存的变化如下:
1 | [0 -> -1] cap = 0 | after append 0 cap = 1 |
1.18之后的扩容规则
-
在分配内存空间之前需要先确定新的切片容量,运行时根据切片的当前容量选择不同的策略进行扩容:
-
如果期望容量大于当前容量的两倍就会使用期望容量;
-
如果当前切片的长度小于阈值(默认 256)就会将容量翻倍;
-
如果当前切片的长度大于等于阈值(默认 256),就会每次增加 25% 的容量,基准是 newcap + 3*threshold,直到新容量大于期望容量;

算出期望扩容后还会内存对齐,会调用roundupsize函数进行内存对齐
1 | var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768} |
假设我们运行此处代码:
1 | s1 := []int{1, 2} |
期望容量是5,但实际会输出6
继续分析可以得出,divRoundUp的结果为 (40 +8 - 1) / 8 = 5, size_to_class8[5] = 5,class_to_size[5] = 48,最终结果capmem为48
具体可以看如下链接扩容后内存对齐是怎么对齐的
执行下述代码
1 | //go 1.18 |
输出结果
1 | === RUN TestSliceGrowing |
go的map底层原理
go中map使用的是渐进性扩容,这样可以避免一次性迁移太多的数据而导致消费过多的时间
go map的结构定义

- 一个map的结构定义如下:
- count:元素个数
- flags:标记位,包括是否扩容,是否有哈希冲突
- B: 表示2的B次方
- buckets:存储键值对的数组,每个bucket是一个bucket结构,存储键值对
- oldbuckets:扩容时使用,指向旧的buckets数组
- hash0:哈希种子
- nevacuate:表示下一次进行迁徙的旧桶编号
- extra:额外的存储空间,指向的是mapextra结构体,存储的是溢出桶的信息
一个bmap大概如下:

其中h1到h8表示tophash,tophash一共由两个作用: 一是状态位,二是存储key值的高八位
tophash作为状态位
1 | emptyRest = 0 // 有两层意思:一是表示该tophash对应的K/V位置是可用的;二是表示该位置后面的K/V位置都是可用的。 |
emptyRest的作用:
-
判断bucket是否为空
当tophash[0]==emptyRest表示整个bucket都是空的,这就是源码里面判断bucket是否为空的方法。 -
查找时快速判断后面位置是否还需遍历
如在查找时,在一个bucket中,找到tophash[2]位置,发现值为emptyRest,就可以判断该bucket没有该元素,继续查找下一个bucket
详细介绍可以看Golang之map tophash详解
hmap
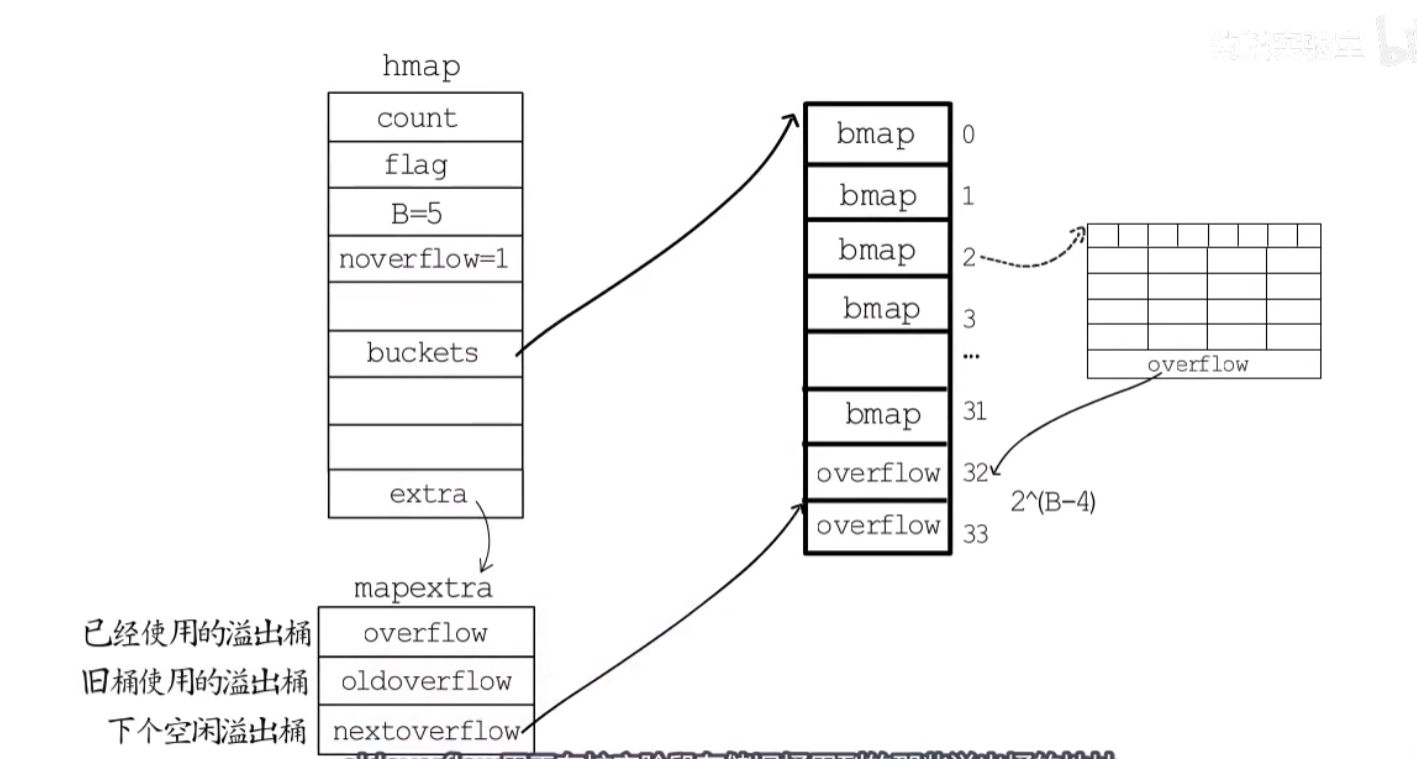
当一个位置的bmap存满了,可能会在其后面添加溢出桶,溢出桶的overflow指向下一个溢出桶的位置,单个桶的容量为8个元素
go map扩容规则
go map扩容规则如下:
- Go语言map的默认负载因子是6.5,也就是说当count/2^B > 6.5时,就会触发翻倍扩容(是旧桶容量的两倍);
- 如果负载因子没有超标,但是使用了太多的溢出桶,就会触发等量扩容,即新桶容量等于旧桶容量;
翻倍扩容
翻倍扩容时,旧桶里的元素会被分流到新的桶中,比如0号桶(旧桶容量是四个)会被分流到新桶的0号或者4号桶中如图所示:
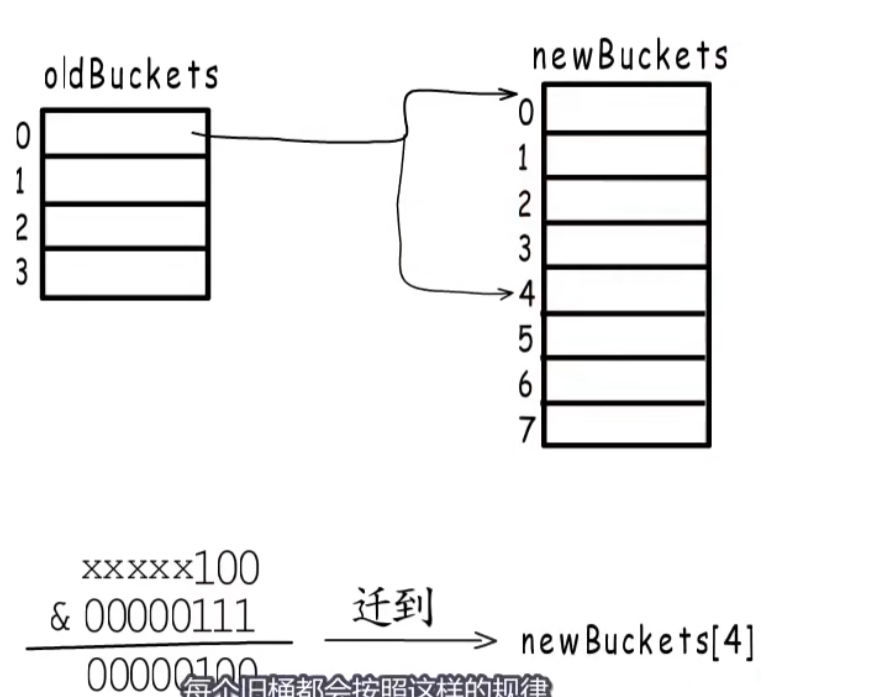
等量扩容
有两个规则:
- 当B<=15, 且常规桶的数量不超过2^15时,溢出桶的数目超过常规桶(2^B),就会触发等量扩容;
- 如果B>15, 且溢出桶的数目超过2^15,就会触发等量扩容;
为什么需要等量扩容?
因为在溢出桶中可能有很多元素被删除了,导致一个溢出桶内只有少量的元素,但是数量没变,这是就需要等量扩容了
函数调用栈
- 在go语言函数栈帧布局中,返回值在函数参数之上,如果一个函数内有defer函数,那么这个函数再放回前是先给放回值赋值,在执行defer函数,如图所示:
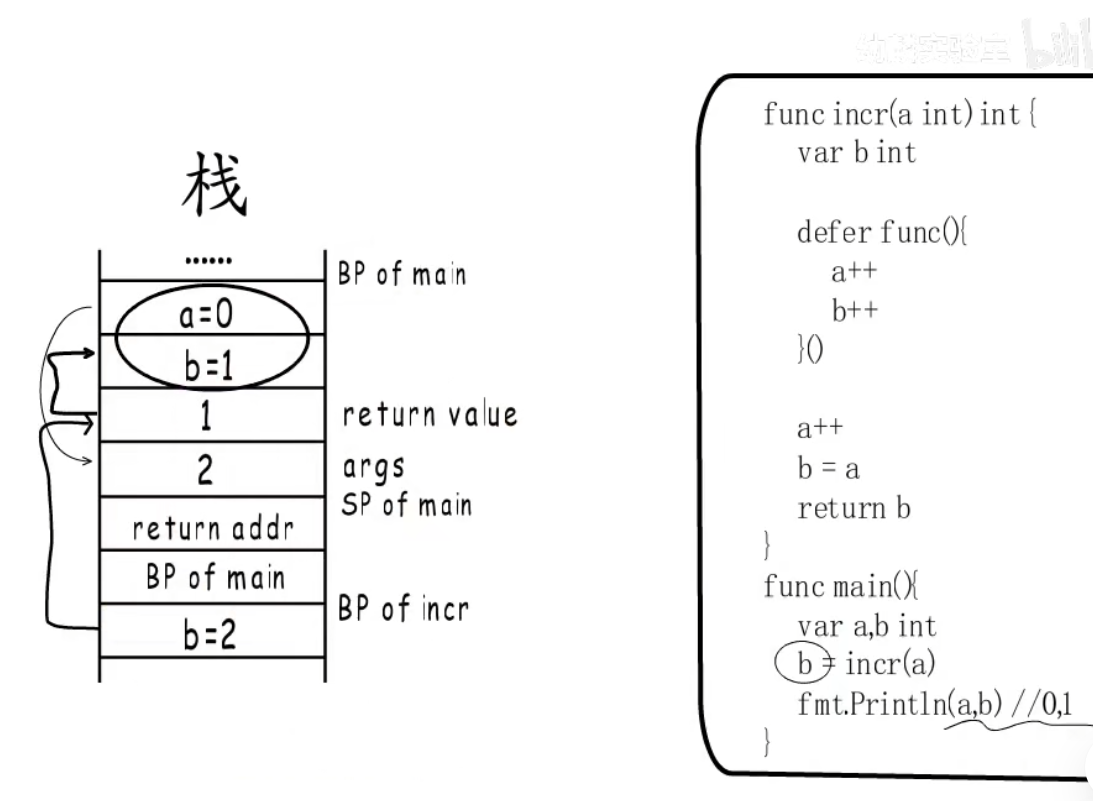
所以上图中main函数中的b为1而不是2
如果使用的是匿名返回值,结果又会不一样
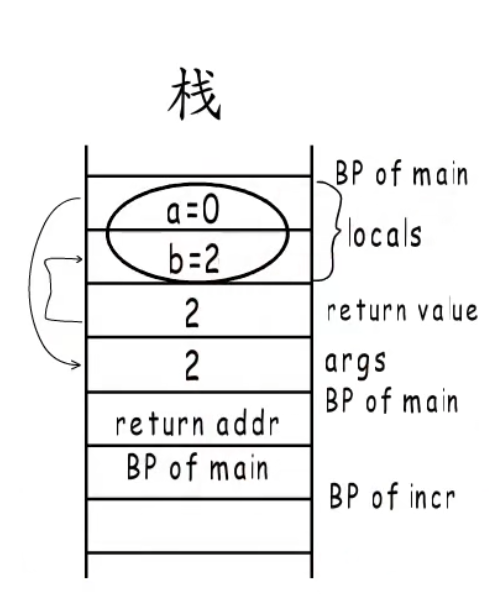
1 | func incr(a int)(b int){ |
- 这个函数中在返回a的时候,a的值为1会赋值给b,此时b也等于1,然后执行defer函数,a再加1,此时a等于2,b也等于2,由于a是局部变量,所以输出为0,2
闭包底层
- 当函数作为返回值或者作为参数以及变量的时候,go语言称这些为function value,function value本质上是一个指针,但是不直接指向函数帧的入口,而是指向一个叫做funcval的结构体,结构体内部为指向函数指令入口地址的指针,也就是说function value本质采用了二级指针的方式,如图所示:

具体例子:
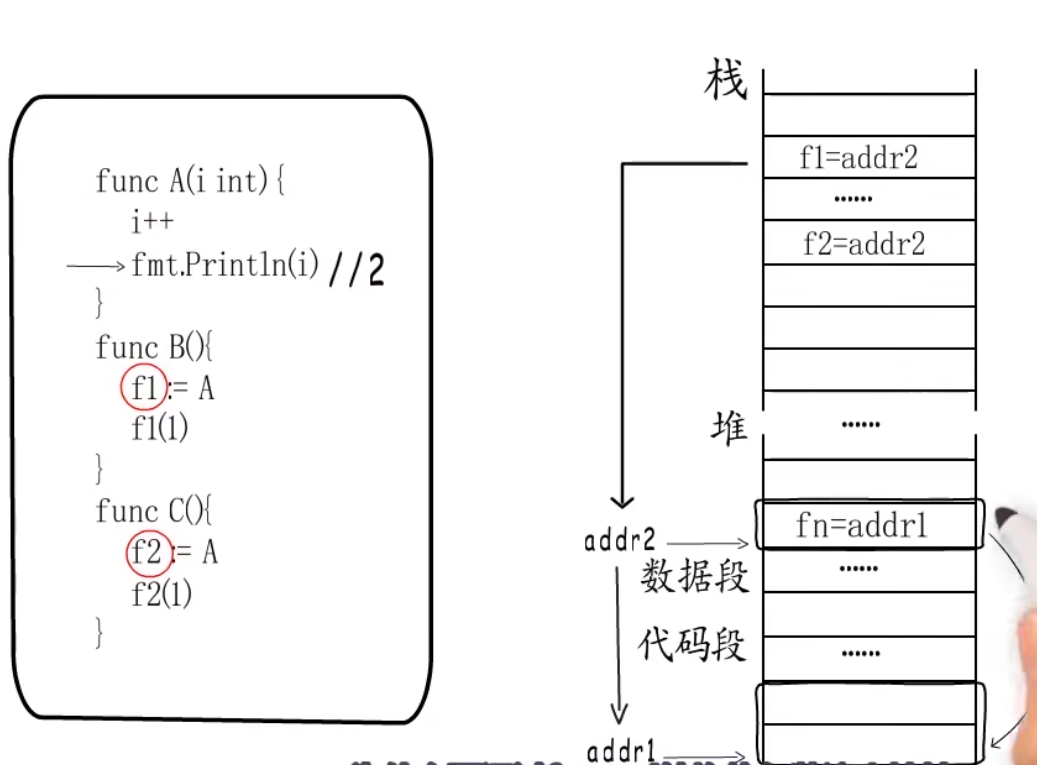
其中addr1为A函数的入口地址,addr2为function value的地址, f1与f2指向的是addr2也就是function value的地址
那么为什么要通过funcval结构体包装函数入口地址,来实现二级指针调用呢?
答案是为闭包服务
闭包函数
补充下闭包的定义:闭包是指一个函数有权访问到其外部函数作用域中的变量
- 闭包函数定义: 当一个函数的返回值是另外一个函数,而返回的那个函数如果调用了其父函数内部的其它变量,如果返回的这个函数在外部被执行,就产生了闭包
例如:
1 | func create() func() int { |
- 闭包函数使用外部变量的时候,会有一个捕获列表,这个捕获列表里面的值就是我捕捉的外部变量
- 捕获列表里面的变量会copy一份外部变量,并且与funcval结构体一块被分配到堆上,堆上的funcval结构体的入口地址就会赋值给函数对象,如图所示:
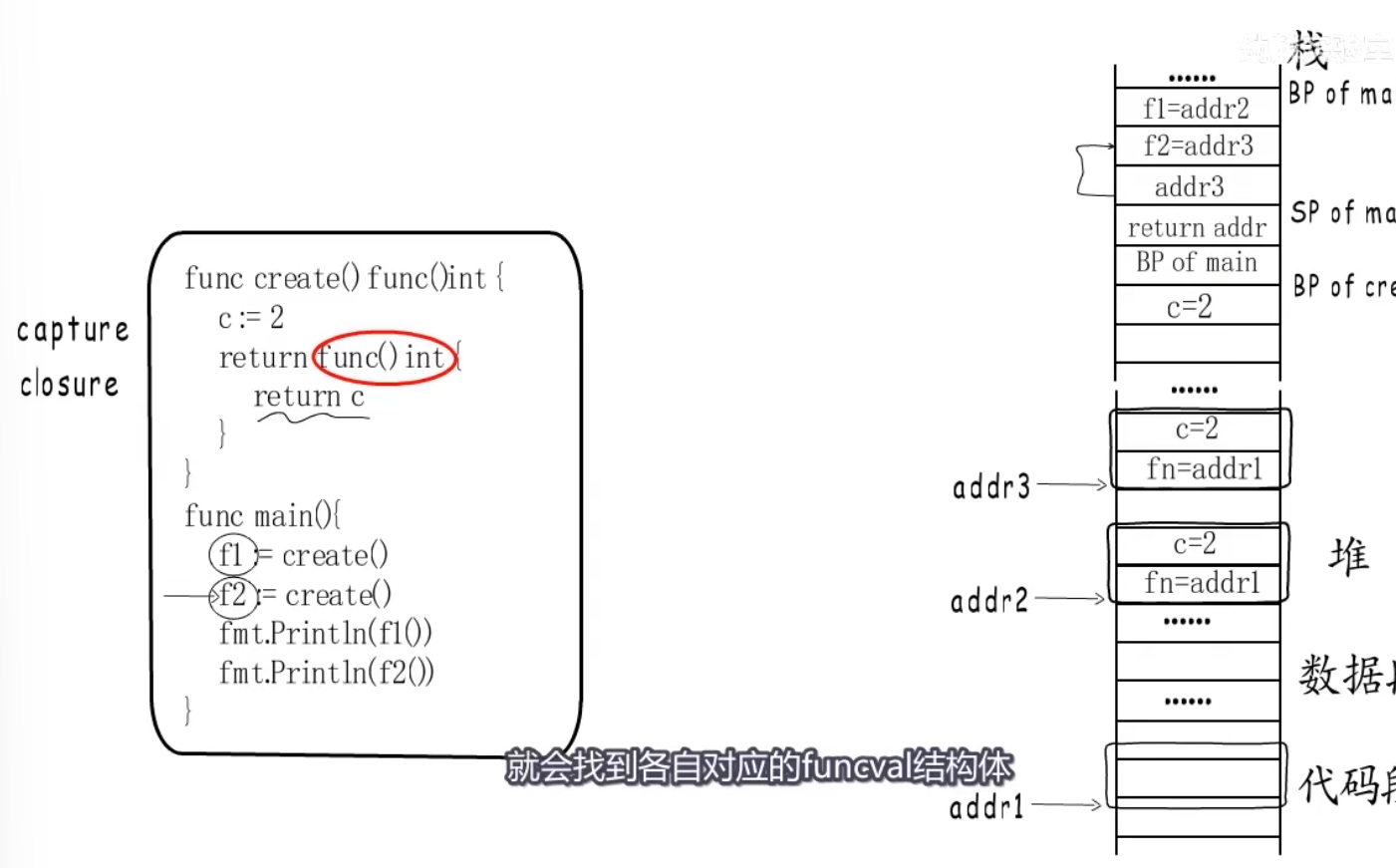
总结来说go语言中闭包就是有捕获列表的Function Value,其是通过寄存器的值来存储Function Value的地址,这样在闭包函数中就能通过寄存器取出funcval结构体的地址,然后加上相应偏离找到捕获变量

在以上图片的例子中,捕获变量除了初始化还会被修改,这是变量就会逃逸到推上,然后fs[0]和fs[1]都使用这个堆上变量,如图所示:
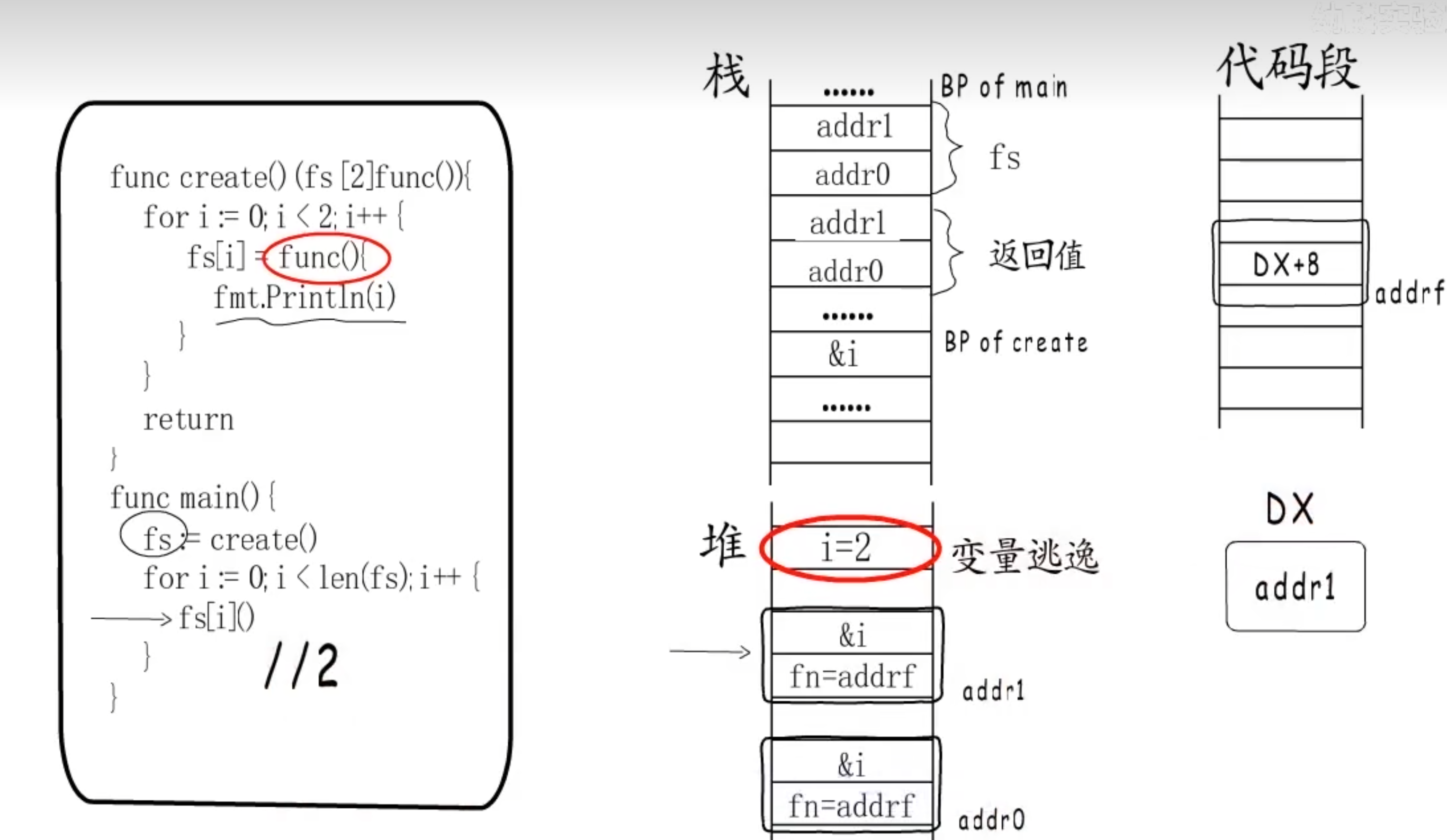
所以函数最终输出都为2
